









Data Secrets
Главный по машинному обучению
Сотрудничество: @veron_28
Реестр: clck.ru/3FY3GN
https://telega.in/c/data_secrets
Сотрудничество: @veron_28
Реестр: clck.ru/3FY3GN
https://telega.in/c/data_secrets
关联群组![Data Secrets [CHAT]](https://static-storm.tglist.com/da1b354b28a3cd215fbc5731e8fd06cb/be92588d-21d4-4364-897a-48b0349874f6.jpg?w=48&h=48)
Data Secrets [CHAT]
3.4K
"Data Secrets" 群组最新帖子
17.05.202508:30
Стрим OpenAI без пасхалок – не стрим OpenAI 🪺

16.05.202515:25
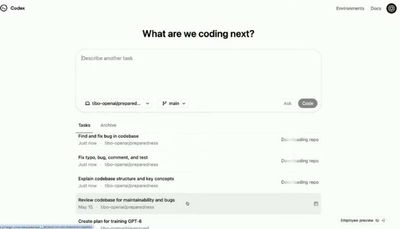
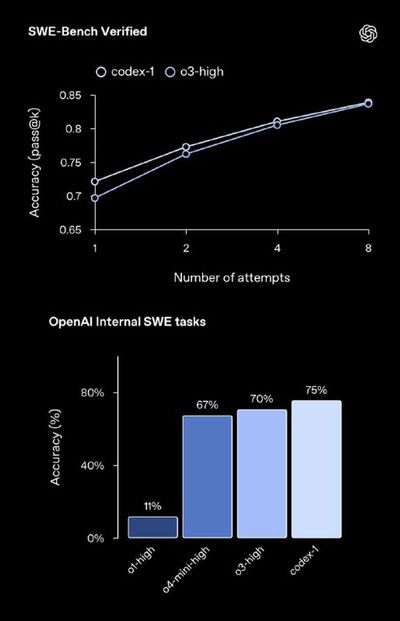
OpenAI представили агента-программиста Codex
Это облачный агент, способный выполнять множество задач параллельно. Из возможностей:
➖Может писать новые функции, отвечать на вопросы по коду, исправлять ошибки и предлагать pull request для ревью.
➖ Каждая задача выполняется в отдельной облачной песочнице, предварительно загруженной вашим репозиторием.
➖Есть возможность настраивать поведение агента через файлы AGENTS. md.
Работает это все на модели Codex-1, основанной на o3. Пока раскатали только для Pro-аккаунтов, для Plus обещают скоро.
Пробуем тут: https://chatgpt.com/codex
Это облачный агент, способный выполнять множество задач параллельно. Из возможностей:
➖Может писать новые функции, отвечать на вопросы по коду, исправлять ошибки и предлагать pull request для ревью.
➖ Каждая задача выполняется в отдельной облачной песочнице, предварительно загруженной вашим репозиторием.
➖Есть возможность настраивать поведение агента через файлы AGENTS. md.
Работает это все на модели Codex-1, основанной на o3. Пока раскатали только для Pro-аккаунтов, для Plus обещают скоро.
Пробуем тут: https://chatgpt.com/codex





16.05.202514:49
Стрим OpenAI через 10 минут. Официально подтверждено: покажут превью агента-программиста Codex (скорее всего доступно будет только в Pro, но все-таки интересно)
https://www.youtube.com/watch?v=hhdpnbfH6NU
https://www.youtube.com/watch?v=hhdpnbfH6NU
16.05.202513:26
Data Fest 2025 в гостях у VK — офлайн 24 мая 🤩
Открываем конференцию Data Fest 2025 — в офисе VK. Приходите познакомиться с опытом дата-инженеров и исследователей в направлениях LLM, NLP, MLOps и других. Эксперты VK подготовили секцию докладов о RecSys, Reliable ML и карьере тимлида. Афтепати с розыгрышем призов и нетворкингом прилагается.
📍 Встречаемся 24 мая по адресу: Ленинградский проспект, 39, стр. 79, БЦ Skylight, башня А.
🤗 Регистрация уже открыта.
Количество мест ограничено, поэтому заполняйте анкету внимательно.
Открываем конференцию Data Fest 2025 — в офисе VK. Приходите познакомиться с опытом дата-инженеров и исследователей в направлениях LLM, NLP, MLOps и других. Эксперты VK подготовили секцию докладов о RecSys, Reliable ML и карьере тимлида. Афтепати с розыгрышем призов и нетворкингом прилагается.
📍 Встречаемся 24 мая по адресу: Ленинградский проспект, 39, стр. 79, БЦ Skylight, башня А.
🤗 Регистрация уже открыта.
Количество мест ограничено, поэтому заполняйте анкету внимательно.


16.05.202510:17
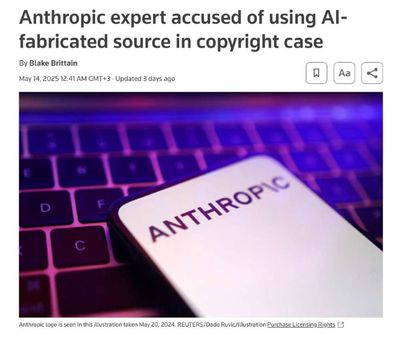
Юрист Anthropic использовал Claude для оформления юридических ссылок. В итоге компании пришлось извиняться.
Прошло почти два года с момента громкой истории о том, как в Америке адвокат чуть не лишился лицензии из-за того, что использовал ChatGPT для генерации аргументов. И... ничего не поменялось 😐
Вот только на этот раз на удочку попался не какой-нибудь случайный юрист, а представитель Anthropic. Сейчас компания судится с Universal Music Group по поводу авторских прав на музыку. И для выступления на суде одна из представителей стартапа, Оливия Чен, решила использовать Claude.
Она попросила бота процитировать для ее показаний соответсвующую статью из законодательства, и он, естественно, все выдумал. В итоге Anthropic пришлось извиняться и за своего юриста, и за галлюцинации своей модели. В официальном письме судье они написали, что "это хотя бы была честная ошибка цитирования, а не попытка подделки авторитета".
Прошло почти два года с момента громкой истории о том, как в Америке адвокат чуть не лишился лицензии из-за того, что использовал ChatGPT для генерации аргументов. И... ничего не поменялось 😐
Вот только на этот раз на удочку попался не какой-нибудь случайный юрист, а представитель Anthropic. Сейчас компания судится с Universal Music Group по поводу авторских прав на музыку. И для выступления на суде одна из представителей стартапа, Оливия Чен, решила использовать Claude.
Она попросила бота процитировать для ее показаний соответсвующую статью из законодательства, и он, естественно, все выдумал. В итоге Anthropic пришлось извиняться и за своего юриста, и за галлюцинации своей модели. В официальном письме судье они написали, что "это хотя бы была честная ошибка цитирования, а не попытка подделки авторитета".

16.05.202508:43
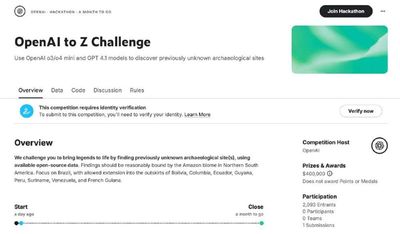
О, Kaggle объединились с OpenAI и запускают конкурс по нахождению ранее неизвестных человечеству археологических объектов
Это, кстати, первое в истории Kaggle ключевое соревнование, то есть оно будет специально выделено как главное на платформе. Призовой фонд – 400 тысяч долларов, за первое место заплатят $250,000 (правда наличными только половину, остальное кредитами OpenAI).
Задача – взять открытые данные со спутниковых снимков и карт + любую модель от OpenAI и предложить пайплайн, который сможет выявлять наличие археологических объектов. Если среди найденных объектов окажутся те, которых нет в существующих базах данных, то можете рассчитывать на приз.
Для трушных Индиан Джонсов
www.kaggle.com/competitions/openai-to-z-challenge/
Это, кстати, первое в истории Kaggle ключевое соревнование, то есть оно будет специально выделено как главное на платформе. Призовой фонд – 400 тысяч долларов, за первое место заплатят $250,000 (правда наличными только половину, остальное кредитами OpenAI).
Задача – взять открытые данные со спутниковых снимков и карт + любую модель от OpenAI и предложить пайплайн, который сможет выявлять наличие археологических объектов. Если среди найденных объектов окажутся те, которых нет в существующих базах данных, то можете рассчитывать на приз.
Для трушных Индиан Джонсов
www.kaggle.com/competitions/openai-to-z-challenge/

16.05.202505:58
Сегодня в 18:00 стрим OpenAI для «разработчиков и тех, кто хочет ими стать»
Напоминаем, что уже во вторник пройдет Google I/O, так что, следуя добрым традициям конкуренции, сегодня OpenAI должны показать что-то заслуживающее внимания.
Может что-то связанное с недавней покупкой Windsurf?
Напоминаем, что уже во вторник пройдет Google I/O, так что, следуя добрым традициям конкуренции, сегодня OpenAI должны показать что-то заслуживающее внимания.
Может что-то связанное с недавней покупкой Windsurf?

15.05.202515:09
Nvidia построит огромный датацентр вместе с ИИ-стартапом Humain из Саудовской Аравии
Компания поставит для этого более 18 тысяч чипов, и не каких-нибудь, а GB300 Blackwell.
Самое интересное, что Humain принадлежит суверенному фонду Саудовской Аравии, то есть по сути – государству. Сегодня совокупные активы фонда оцениваются в 430 миллиардов долларов.
Nvidia видимо решили действовать по-крупному, пока и туда поставки не запретили
Компания поставит для этого более 18 тысяч чипов, и не каких-нибудь, а GB300 Blackwell.
Самое интересное, что Humain принадлежит суверенному фонду Саудовской Аравии, то есть по сути – государству. Сегодня совокупные активы фонда оцениваются в 430 миллиардов долларов.
Nvidia видимо решили действовать по-крупному, пока и туда поставки не запретили


15.05.202514:02
Выбираете магистратуру? Обратите внимание на бесплатные партнёрские программы Яндекса в топовых вузах России!
🔹 «Аппаратная разработка умных устройств» — межуниверситетская магистратура в НИУ ВШЭ и МФТИ. Вы будете решать реальные задачи, с которыми работают инженеры сервиса «Алиса и Умные устройства Яндекса».
🔹 «Искусственный интеллект в робототехнике» — программа в Сколтехе, основанная на опыте Яндекс Маркета. Вас ждёт работа с кейсами, где ИИ меняет процесс логистики и автоматизации.
Программы разрабатывались при участии экспертов Яндекса — действующих практиков в ML и Data Science, а также опытных преподавателей, — поэтому обучение построено на самых актуальных знаниях и реальных задачах.
🚀 Если хотите не просто получить диплом, а вырасти в сильного специалиста, переходите на сайт и выбирайте программу!
🔹 «Аппаратная разработка умных устройств» — межуниверситетская магистратура в НИУ ВШЭ и МФТИ. Вы будете решать реальные задачи, с которыми работают инженеры сервиса «Алиса и Умные устройства Яндекса».
🔹 «Искусственный интеллект в робототехнике» — программа в Сколтехе, основанная на опыте Яндекс Маркета. Вас ждёт работа с кейсами, где ИИ меняет процесс логистики и автоматизации.
Программы разрабатывались при участии экспертов Яндекса — действующих практиков в ML и Data Science, а также опытных преподавателей, — поэтому обучение построено на самых актуальных знаниях и реальных задачах.
🚀 Если хотите не просто получить диплом, а вырасти в сильного специалиста, переходите на сайт и выбирайте программу!


15.05.202512:03
DeepSeek выпустили новую статью, в которой поделились большим списком инженерных хаков по обучению и инференсу моделей
Все, что не убивает, делает сильнее. DeepSeek в условиях санкций на оборудование уже собрали целый список того, что помогает им даже при большом дефиците железа содержать свои системы и обучать модели. Ну и, как истинные любители открытости, всеми этими фичами они решили поделиться просто так.
Топ-3:
1. Multi-head Latent Attention. Это метод сжатия KV-кеша, позволяющий радикально сократить объём памяти, необходимый для хранения ключей и значений из всех attention-голов. Идея в том, чтобы вместо хранения всех сырых K/V векторов для каждого хэдa проектировать их в компактный обучающийся латентный вектор небольшой размерности. В итоге вместо квадратичного роста хранимых данных получается линейный.
2. FP8 Mixed-Precision Training и Inference. Инженерная стратегия, которая позволяет при обучении модели одновременно использовать и более легкие числа в формате FP8, и более точные в FP16 / FP22/FP32. Так мы балансируем между производительностью и стабильностью, а затраты и энергопотребление падают почти в два раза.
3. Multi-Token Prediction. Это значит, что вместо генерации по одному токену модель пытается предсказать сразу несколько (например 2–4) следующих токена. Токены-кандидаты генерирует отдельный легковесный слой, а основная модель их просто сверяет с истинным декодингом. Если совпадают – принимаются без дорасчёта. Это дает ускорение инференса до 1.8х без потерь в качестве.
В статье – еще несколько интересных советов (некоторые мы даже уже разбирали во время опенсорса DeepSeek), так что трушным инженерам советуем почитать полностью.
Мир им: строгие запреты на ввоз железа
Они всему миру: детальные открытые советы по оптимизации этого железа
Респект же
Все, что не убивает, делает сильнее. DeepSeek в условиях санкций на оборудование уже собрали целый список того, что помогает им даже при большом дефиците железа содержать свои системы и обучать модели. Ну и, как истинные любители открытости, всеми этими фичами они решили поделиться просто так.
Топ-3:
1. Multi-head Latent Attention. Это метод сжатия KV-кеша, позволяющий радикально сократить объём памяти, необходимый для хранения ключей и значений из всех attention-голов. Идея в том, чтобы вместо хранения всех сырых K/V векторов для каждого хэдa проектировать их в компактный обучающийся латентный вектор небольшой размерности. В итоге вместо квадратичного роста хранимых данных получается линейный.
2. FP8 Mixed-Precision Training и Inference. Инженерная стратегия, которая позволяет при обучении модели одновременно использовать и более легкие числа в формате FP8, и более точные в FP16 / FP22/FP32. Так мы балансируем между производительностью и стабильностью, а затраты и энергопотребление падают почти в два раза.
3. Multi-Token Prediction. Это значит, что вместо генерации по одному токену модель пытается предсказать сразу несколько (например 2–4) следующих токена. Токены-кандидаты генерирует отдельный легковесный слой, а основная модель их просто сверяет с истинным декодингом. Если совпадают – принимаются без дорасчёта. Это дает ускорение инференса до 1.8х без потерь в качестве.
В статье – еще несколько интересных советов (некоторые мы даже уже разбирали во время опенсорса DeepSeek), так что трушным инженерам советуем почитать полностью.
Мир им: строгие запреты на ввоз железа
Они всему миру: детальные открытые советы по оптимизации этого железа
Респект же


15.05.202509:31
Случился коллаб года: Kaggle объединились с HuggingFace и теперь все модели, доступные на HF, можно моментально напрямую запускать в Kaggle Notebooks
Этим можно пользоваться и на одной платформе, и на другой. Например, если вы перешли в карточку модели на HF, то теперь там можно ткнуть на “Use this model” -> “Kaggle”, и сразу откроется ноутбук с подгруженной моделью.
То же самое можно сделать с вкладки HuggingFace на Kaggle по кнопке "Code". Также там будут видны все открытые относящиеся к этой модели ноутбуки других пользователей.
Обещают, что скоро будут и другие интересные фичи
Этим можно пользоваться и на одной платформе, и на другой. Например, если вы перешли в карточку модели на HF, то теперь там можно ткнуть на “Use this model” -> “Kaggle”, и сразу откроется ноутбук с подгруженной моделью.
То же самое можно сделать с вкладки HuggingFace на Kaggle по кнопке "Code". Также там будут видны все открытые относящиеся к этой модели ноутбуки других пользователей.
Обещают, что скоро будут и другие интересные фичи


15.05.202507:58
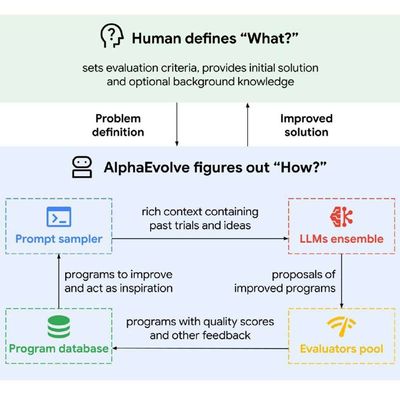
Google анонсировали кодинг-агента AlphaEvolve, предназначенного специально для разработки сложных алгоритмов
Инженеры утверждают, что на тестах этой системе удалось:
– Идентифицировать несколько абсолютно новых алгоритмов для эффективного умножения матриц. Один из них даже оказался эффективнее известного алгоритма Штрассена (1969, кстати).
– В 75% найти лучшие известные на данный момент решения открытых мировых задач по математике, и в 20% улучшить ранее известные решения (то есть открыть новые подходы).
И это не все. Внутри экосистемы Google AlphaEvolve работает уже год. За это время с его помощью они успели оптимизировать несколько датацентров, обучение и инференс моделей и даже использовали ассистента для проектирования железа.
Под капотом цикл: обработка контекста -> генерация идей и решений -> оценка и скоринг этих решений -> добавление лучших решений в контекст для дальнейшего улучшения -> и с начала.
Потрогать пока, конечно, не дают, поэтому будем ждать
deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/
Инженеры утверждают, что на тестах этой системе удалось:
– Идентифицировать несколько абсолютно новых алгоритмов для эффективного умножения матриц. Один из них даже оказался эффективнее известного алгоритма Штрассена (1969, кстати).
– В 75% найти лучшие известные на данный момент решения открытых мировых задач по математике, и в 20% улучшить ранее известные решения (то есть открыть новые подходы).
И это не все. Внутри экосистемы Google AlphaEvolve работает уже год. За это время с его помощью они успели оптимизировать несколько датацентров, обучение и инференс моделей и даже использовали ассистента для проектирования железа.
Под капотом цикл: обработка контекста -> генерация идей и решений -> оценка и скоринг этих решений -> добавление лучших решений в контекст для дальнейшего улучшения -> и с начала.
Потрогать пока, конечно, не дают, поэтому будем ждать
deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/

14.05.202518:38
GPT-4.1 добавили в ChatGPT
Напоминаем, что это лучшая не-ризонинг модель стартапа для программирования, она обгоняет даже o1-high. Плюс контекст 1 миллион токенов.
Ранее модель была доступна только в API и через сторонних вендоров типа Cursor. Но, видимо, спрос был настолько велик, что ее добавили и в чат.
🍯 Модель уже раскатали на Plus, Pro и Team, а мини-версия – GPT-4.1 mini – скоро заменит GPT-4o mini для всех, включая бесплатных юзеров.
Напоминаем, что это лучшая не-ризонинг модель стартапа для программирования, она обгоняет даже o1-high. Плюс контекст 1 миллион токенов.
Ранее модель была доступна только в API и через сторонних вендоров типа Cursor. Но, видимо, спрос был настолько велик, что ее добавили и в чат.
🍯 Модель уже раскатали на Plus, Pro и Team, а мини-версия – GPT-4.1 mini – скоро заменит GPT-4o mini для всех, включая бесплатных юзеров.


14.05.202515:03
Радостные новости: Anthropic все-таки выпустит новый Claude Opus
В прошлых релизах приставка Opus означала самую большую модель, а Sonnet – среднюю. Но начиная с версии 3.5 Opus не выходил – был только Sonnet и Haiku, а из ризонинг моделей вообще один Sonnet.
Но The Information только что написали, что линейка Opus может возродиться, и новые ризонинг модели Opus и Sonnet выйдут уже в ближайшие недели.
Более того, это будут какие-то необычные ризонинг-модели: в них будет режим «экстремальных рассуждений». Модель будет работать в цикле: думать -> обращаться к инструментам (интерпретатор или браузер) -> снова думать, анализируя результаты -> снова обращаться к инструментам и тд. В общем, что-то ближе к агентам.
www.theinformation.com/articles/anthropics-upcoming-models-will-think-think
В прошлых релизах приставка Opus означала самую большую модель, а Sonnet – среднюю. Но начиная с версии 3.5 Opus не выходил – был только Sonnet и Haiku, а из ризонинг моделей вообще один Sonnet.
Но The Information только что написали, что линейка Opus может возродиться, и новые ризонинг модели Opus и Sonnet выйдут уже в ближайшие недели.
Более того, это будут какие-то необычные ризонинг-модели: в них будет режим «экстремальных рассуждений». Модель будет работать в цикле: думать -> обращаться к инструментам (интерпретатор или браузер) -> снова думать, анализируя результаты -> снова обращаться к инструментам и тд. В общем, что-то ближе к агентам.
www.theinformation.com/articles/anthropics-upcoming-models-will-think-think


14.05.202514:02
7–8 июня проводим Weekend Offer Analytics
Устроиться в Яндекс за выходные — реально. Ищем крутых аналитиков с опытом работы от 3 лет на Python, готовых работать в офисном или гибридном режиме.
Подавайте заявку до 3 июня — и всего за 2 дня пройдите технические собеседования. После сможете пообщаться с двенадцатью нанимающими командами и выбрать ту, которая покажется самой интересной. Если всё сложится хорошо, сразу же пришлём вам офер.
Узнать подробности и зарегистрироваться.
Реклама. ООО "Яндекс". ИНН 7736207543
Устроиться в Яндекс за выходные — реально. Ищем крутых аналитиков с опытом работы от 3 лет на Python, готовых работать в офисном или гибридном режиме.
Подавайте заявку до 3 июня — и всего за 2 дня пройдите технические собеседования. После сможете пообщаться с двенадцатью нанимающими командами и выбрать ту, которая покажется самой интересной. Если всё сложится хорошо, сразу же пришлём вам офер.
Узнать подробности и зарегистрироваться.
Реклама. ООО "Яндекс". ИНН 7736207543





+2
12.05.202507:37
Пу-пу-пу, тот самый понедельник после майских. Чтобы немного поднять всем настроение, несем с утра приятную новость
Пока все отдыхали на шашлыках, мы с командой торопились поскорее закончить для вас кое-что особенное. И это – большой конспект по большим языковым моделям.
Внутри – все, что нужно, чтобы от А до Я понять, как работают современные LLM:
– необходимая математика
– механизм внимания и трансформеры со схемами и интуитивными примерами
– все про предобучение
– основы и алгоритмы RL + ризонинг
– ... и даже полноценный гайд по тому, как самостоятельно зафайнтюнить модель.
По секрету: работа над конспектом заняла у нас больше месяца.
500 🔥 и завтра мы выложим сюда полную pdf-версию
Пока все отдыхали на шашлыках, мы с командой торопились поскорее закончить для вас кое-что особенное. И это – большой конспект по большим языковым моделям.
Внутри – все, что нужно, чтобы от А до Я понять, как работают современные LLM:
– необходимая математика
– механизм внимания и трансформеры со схемами и интуитивными примерами
– все про предобучение
– основы и алгоритмы RL + ризонинг
– ... и даже полноценный гайд по тому, как самостоятельно зафайнтюнить модель.
По секрету: работа над конспектом заняла у нас больше месяца.
500 🔥 и завтра мы выложим сюда полную pdf-версию


20.04.202508:58
Там Стэнфорд выложили на YouTube свой свежий курс CS336: Language Modeling from Scratch
Это практический курс, в котором вся теория по LLM подается в процессе разработки собственной модели. Получается изучение end-to-end: от обработки данных и архитектуры трансформера до RL и эвала.
Ведет курс опытный профессор университета и сооснователь TogetherAI Перси Лианг.
Ну и главное: курс новый и вся информация актуальна на сегодняшний день. Он даже в самом Стэнфорде еще идет прямо сейчас, так что лекции и код продолжат выкладывать по ходу.
Репозиторий с дз и ноутбуками
Сайт курса
YouTube
Это практический курс, в котором вся теория по LLM подается в процессе разработки собственной модели. Получается изучение end-to-end: от обработки данных и архитектуры трансформера до RL и эвала.
Ведет курс опытный профессор университета и сооснователь TogetherAI Перси Лианг.
Ну и главное: курс новый и вся информация актуальна на сегодняшний день. Он даже в самом Стэнфорде еще идет прямо сейчас, так что лекции и код продолжат выкладывать по ходу.
Репозиторий с дз и ноутбуками
Сайт курса
YouTube


23.04.202511:39
Anthropic выкатили гайд по вайб-кодингу 😎
23 страницы посвящены тому, как программировать с агентами (в частности, с Claude Code). Собраны советы, best practices, примеры, антипримеры и даже готовые промпты.
Отдельное внимание уделяется безопасности данных и мульти-агентным процессам.
Полезно, если пользуетесь каким-нибудь подобным инструментом каждый день
PDF
23 страницы посвящены тому, как программировать с агентами (в частности, с Claude Code). Собраны советы, best practices, примеры, антипримеры и даже готовые промпты.
Отдельное внимание уделяется безопасности данных и мульти-агентным процессам.
Полезно, если пользуетесь каким-нибудь подобным инструментом каждый день


18.04.202509:03
OpenAI выкатили 32-страничный практический гайд по разработке агентов
Его создавали сами инженеры из продуктовых команд стартапа.
Внутри теоретические основы, шаблоны проектирования, лучшие тактики для безопасного развертывания и мониторинга, а главное много-много примеров.
Забираем мастрид на выходные: cdn.openai.com/business-guides-and-resources/a-practical-guide-to-building-agents.pdf
Его создавали сами инженеры из продуктовых команд стартапа.
Внутри теоретические основы, шаблоны проектирования, лучшие тактики для безопасного развертывания и мониторинга, а главное много-много примеров.
Забираем мастрид на выходные: cdn.openai.com/business-guides-and-resources/a-practical-guide-to-building-agents.pdf


25.04.202515:10
Мотивации пост: сейчас в топ-1 по популярности на Hugging Face висит модель, которую разработала команда… из двух человек
Лаборатория называется Nari Labs, и она действительно состоит всего из двух исследователей. Несмотря на это, на этой неделе они со своей text2speech моделью DIA оставили позади Microsoft, Anthropic, Nvidia и другие корпорации.
Моделька у них правда крутая. В ней всего 1.6B параметров, но она генерирует из текста очень качественные диалоги. Сохраняет даже смех, кашель и вздохи. Плюс, пользователь может управлять эмоциями.
При этом у ребят действительно понятная и красивая карточка модели и хорошо оформленный код на гитхаб. Респект?
Лаборатория называется Nari Labs, и она действительно состоит всего из двух исследователей. Несмотря на это, на этой неделе они со своей text2speech моделью DIA оставили позади Microsoft, Anthropic, Nvidia и другие корпорации.
Моделька у них правда крутая. В ней всего 1.6B параметров, но она генерирует из текста очень качественные диалоги. Сохраняет даже смех, кашель и вздохи. Плюс, пользователь может управлять эмоциями.
При этом у ребят действительно понятная и красивая карточка модели и хорошо оформленный код на гитхаб. Респект?






13.05.202507:31
LLM превзошли врачей на новом бенчмарке OpenAI по медицине
HealthBench вышел вчера и состоит не просто из вопросов, а из синтетических диалогов между ассистентом и пользователем. Каждый такой диалог заканчивается сообщением пользователя, на который уже тестируемая модель должна ответить.
Таких диалогов аж 5000 и они разрабатывались совместно с 262 врачами из 26 разных областей. Ответы оцениваются по пяти осям: точность, полнота, понимание контекста, качество коммуникации и следование инструкциям.
Вот какие результаты получились:
➖ Самой эффективной моделью оказалась o3 с результатом 60%. Сразу за ней Grok-3 (54%) и Gemini 2.5 Pro (52%)
➖ У живых врачей результаты сильно ниже. Без опоры на ИИ-ответы люди набирают около 13%.
➖ При этом люди затрудняются даже улучшить ответы ИИ. Смотрите график 3: если дать медикам посмотреть на несколько ответов моделей из сентябрьского поколения и попросить написать на их основе идеальный ответ, люди улучшают средний скор на несколько процентных пунктов (0.31 против 0.28). Но с новыми апрельскими моделями так уже не работает: люди только ухудшают ответы ИИ (0.48 против 0.49).
Кстати, еще менее года назад GPT-3.5 Turbo выбивал всего 16%. Интересно, что будет еще через год.
cdn.openai.com/pdf/bd7a39d5-9e9f-47b3-903c-8b847ca650c7/healthbench_paper.pdf
HealthBench вышел вчера и состоит не просто из вопросов, а из синтетических диалогов между ассистентом и пользователем. Каждый такой диалог заканчивается сообщением пользователя, на который уже тестируемая модель должна ответить.
Таких диалогов аж 5000 и они разрабатывались совместно с 262 врачами из 26 разных областей. Ответы оцениваются по пяти осям: точность, полнота, понимание контекста, качество коммуникации и следование инструкциям.
Вот какие результаты получились:
➖ Самой эффективной моделью оказалась o3 с результатом 60%. Сразу за ней Grok-3 (54%) и Gemini 2.5 Pro (52%)
➖ У живых врачей результаты сильно ниже. Без опоры на ИИ-ответы люди набирают около 13%.
➖ При этом люди затрудняются даже улучшить ответы ИИ. Смотрите график 3: если дать медикам посмотреть на несколько ответов моделей из сентябрьского поколения и попросить написать на их основе идеальный ответ, люди улучшают средний скор на несколько процентных пунктов (0.31 против 0.28). Но с новыми апрельскими моделями так уже не работает: люди только ухудшают ответы ИИ (0.48 против 0.49).
Кстати, еще менее года назад GPT-3.5 Turbo выбивал всего 16%. Интересно, что будет еще через год.
cdn.openai.com/pdf/bd7a39d5-9e9f-47b3-903c-8b847ca650c7/healthbench_paper.pdf
15.05.202512:03
DeepSeek выпустили новую статью, в которой поделились большим списком инженерных хаков по обучению и инференсу моделей
Все, что не убивает, делает сильнее. DeepSeek в условиях санкций на оборудование уже собрали целый список того, что помогает им даже при большом дефиците железа содержать свои системы и обучать модели. Ну и, как истинные любители открытости, всеми этими фичами они решили поделиться просто так.
Топ-3:
1. Multi-head Latent Attention. Это метод сжатия KV-кеша, позволяющий радикально сократить объём памяти, необходимый для хранения ключей и значений из всех attention-голов. Идея в том, чтобы вместо хранения всех сырых K/V векторов для каждого хэдa проектировать их в компактный обучающийся латентный вектор небольшой размерности. В итоге вместо квадратичного роста хранимых данных получается линейный.
2. FP8 Mixed-Precision Training и Inference. Инженерная стратегия, которая позволяет при обучении модели одновременно использовать и более легкие числа в формате FP8, и более точные в FP16 / FP22/FP32. Так мы балансируем между производительностью и стабильностью, а затраты и энергопотребление падают почти в два раза.
3. Multi-Token Prediction. Это значит, что вместо генерации по одному токену модель пытается предсказать сразу несколько (например 2–4) следующих токена. Токены-кандидаты генерирует отдельный легковесный слой, а основная модель их просто сверяет с истинным декодингом. Если совпадают – принимаются без дорасчёта. Это дает ускорение инференса до 1.8х без потерь в качестве.
В статье – еще несколько интересных советов (некоторые мы даже уже разбирали во время опенсорса DeepSeek), так что трушным инженерам советуем почитать полностью.
Мир им: строгие запреты на ввоз железа
Они всему миру: детальные открытые советы по оптимизации этого железа
Респект же
Все, что не убивает, делает сильнее. DeepSeek в условиях санкций на оборудование уже собрали целый список того, что помогает им даже при большом дефиците железа содержать свои системы и обучать модели. Ну и, как истинные любители открытости, всеми этими фичами они решили поделиться просто так.
Топ-3:
1. Multi-head Latent Attention. Это метод сжатия KV-кеша, позволяющий радикально сократить объём памяти, необходимый для хранения ключей и значений из всех attention-голов. Идея в том, чтобы вместо хранения всех сырых K/V векторов для каждого хэдa проектировать их в компактный обучающийся латентный вектор небольшой размерности. В итоге вместо квадратичного роста хранимых данных получается линейный.
2. FP8 Mixed-Precision Training и Inference. Инженерная стратегия, которая позволяет при обучении модели одновременно использовать и более легкие числа в формате FP8, и более точные в FP16 / FP22/FP32. Так мы балансируем между производительностью и стабильностью, а затраты и энергопотребление падают почти в два раза.
3. Multi-Token Prediction. Это значит, что вместо генерации по одному токену модель пытается предсказать сразу несколько (например 2–4) следующих токена. Токены-кандидаты генерирует отдельный легковесный слой, а основная модель их просто сверяет с истинным декодингом. Если совпадают – принимаются без дорасчёта. Это дает ускорение инференса до 1.8х без потерь в качестве.
В статье – еще несколько интересных советов (некоторые мы даже уже разбирали во время опенсорса DeepSeek), так что трушным инженерам советуем почитать полностью.
Мир им: строгие запреты на ввоз железа
Они всему миру: детальные открытые советы по оптимизации этого железа
Респект же




04.05.202509:00
Исследователи из Университета Карнеги-Меллон создали IT-компанию, полностью состоящую из ИИ-агентов. Вот что из этого вышло
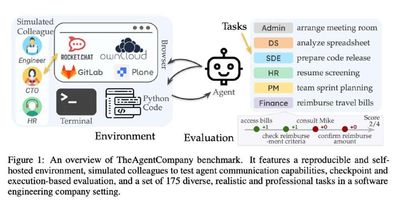
Команда исследователей из CMU запустила необычный эксперимент: они создали автономную виртуальную среду, имитирующую небольшую software компанию, и поместили на "реальные" рабочие места современных LLM-агентов. Все оформили в виде бенчмарка и назвали TheAgentCompany.
По сути агенту необходимо делать все то же, что делает типичный работчик IT (картинка 1): писать код, использовать терминал, рыться в браузере и Google Drive, взамодействовать с коллегами в мессенджере, пользоваться GitLab и Jira. Выполнение всех задач, кстати, оценивалось по чекпоинтам, а не просто "выполнил/не выполнил" (картинка 2) + учитывали итоговую стоимость по токенам.
В компании успели поработать Claude 3.5 Sonnet, Gemini-2.0 Flash, GPT-4o, Gemini-1.5-Pro, Llama-3.3 и 3.1, Qwen-2.5 и другие. Задачи покрывали SWE, PM, HR и еще несколько классических сфер. Всего 175 тасок, рассчитанных на 3000 часов труда 20 живых людей.
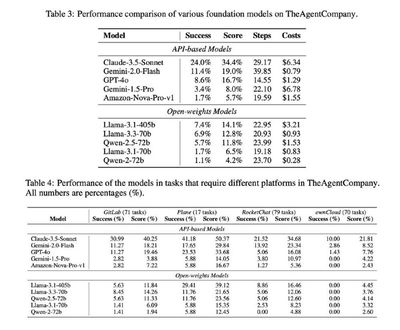
Результаты в таблицах на картинке 3. Как видите, даже лучший Claude 3.5 Sonnet справляется только с четвертью базовых обязанностей. Следующум идет Gemini 2.0 Flash, но уже с большим отрывом: 11.4%. Все остальные – меньше 9%.
Забавно, что GitLab и кодинг давались агентам довольно легко, а вот самым сложным оказались банальные заполнения форм, браузинг, планирование встреч и общение в мессенджере (им просто не объяснили, что надо мемы отправлять).
Хороший бенч, побольше бы таких
Статья | Код | Сайт (лидерборд внутри) | Результаты экспериментов
Команда исследователей из CMU запустила необычный эксперимент: они создали автономную виртуальную среду, имитирующую небольшую software компанию, и поместили на "реальные" рабочие места современных LLM-агентов. Все оформили в виде бенчмарка и назвали TheAgentCompany.
По сути агенту необходимо делать все то же, что делает типичный работчик IT (картинка 1): писать код, использовать терминал, рыться в браузере и Google Drive, взамодействовать с коллегами в мессенджере, пользоваться GitLab и Jira. Выполнение всех задач, кстати, оценивалось по чекпоинтам, а не просто "выполнил/не выполнил" (картинка 2) + учитывали итоговую стоимость по токенам.
В компании успели поработать Claude 3.5 Sonnet, Gemini-2.0 Flash, GPT-4o, Gemini-1.5-Pro, Llama-3.3 и 3.1, Qwen-2.5 и другие. Задачи покрывали SWE, PM, HR и еще несколько классических сфер. Всего 175 тасок, рассчитанных на 3000 часов труда 20 живых людей.
Результаты в таблицах на картинке 3. Как видите, даже лучший Claude 3.5 Sonnet справляется только с четвертью базовых обязанностей. Следующум идет Gemini 2.0 Flash, но уже с большим отрывом: 11.4%. Все остальные – меньше 9%.
Забавно, что GitLab и кодинг давались агентам довольно легко, а вот самым сложным оказались банальные заполнения форм, браузинг, планирование встреч и общение в мессенджере (им просто не объяснили, что надо мемы отправлять).
Хороший бенч, побольше бы таких
Статья | Код | Сайт (лидерборд внутри) | Результаты экспериментов


24.04.202517:40
❤️ – говорю спасибо, верю в карму
👍 – не говорю спасибо, <strike>я бессмертный</strike> берегу лимиты
👍 – не говорю спасибо, <strike>я бессмертный</strike> берегу лимиты

26.04.202509:16
Paper2Code: исследователи из корейского технологического института сделали мульти-агентный фрейморк для автоматической генерации кода по статьям
Боль каждого рисерчера – это статьи, к которым нет кода. Чтобы воспроизвести результат, нужно потратить пол жизни, и то – успех не гарантирован. А код авторы публикуют не так уж и часто. На примере NeurIPS, ICML и ICLR 2024: только 21.2% принятых работ имеют открытые репы.
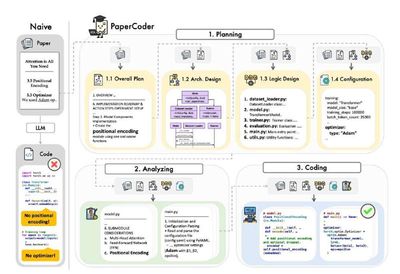
Здесь авторы предлагают PaperCoder. Это мульти-агентная система, в которой процесс генерации репозитория разбит на три этапа:
1. Планирование. Составляется конспект статьи, UML-диаграммы классов + список файлов. Тут же создается config.yaml с гиперпараметрами и выстраивается план последовательности генерации.
2. Анализ. Здесь для каждого файла из составленного списка формируется file-level analysis — подробное описание целей, входов/выходов, взаимодействий и каких-то специфичных требований, если есть.
3. Ну и сама генерация на основании статьи, фазы планирования и анализа. Бонусом из первых двух пунктов получаем супер-подробную доку.
На каждом шаге работает отдельный агент. Это, по идее, могут быть разные LLM, но здесь по умолчанию на всех шагах стоит o3-mini-high (кроме валидации, там GPT-4o).
Тестировали на работах с тех же ICML/NeurIPS/ICLR 2024. Процент полностью успешной репликации – около 44% против 10-15 у базовых агентов. Если анализировать вручную, то в среднем для успешного запуска нужно менять всего 0.48 % строк. А еще PaperCoder давали потрогать исследователям, и в 85% случаев те сказали, что это лучше, чем писать с нуля, даже если нужно что-то дебажить.
Ирония только в том, что к статье Paper2Code... не выложили код. Но, вроде, обещают "скоро"
Боль каждого рисерчера – это статьи, к которым нет кода. Чтобы воспроизвести результат, нужно потратить пол жизни, и то – успех не гарантирован. А код авторы публикуют не так уж и часто. На примере NeurIPS, ICML и ICLR 2024: только 21.2% принятых работ имеют открытые репы.
Здесь авторы предлагают PaperCoder. Это мульти-агентная система, в которой процесс генерации репозитория разбит на три этапа:
1. Планирование. Составляется конспект статьи, UML-диаграммы классов + список файлов. Тут же создается config.yaml с гиперпараметрами и выстраивается план последовательности генерации.
2. Анализ. Здесь для каждого файла из составленного списка формируется file-level analysis — подробное описание целей, входов/выходов, взаимодействий и каких-то специфичных требований, если есть.
3. Ну и сама генерация на основании статьи, фазы планирования и анализа. Бонусом из первых двух пунктов получаем супер-подробную доку.
На каждом шаге работает отдельный агент. Это, по идее, могут быть разные LLM, но здесь по умолчанию на всех шагах стоит o3-mini-high (кроме валидации, там GPT-4o).
Тестировали на работах с тех же ICML/NeurIPS/ICLR 2024. Процент полностью успешной репликации – около 44% против 10-15 у базовых агентов. Если анализировать вручную, то в среднем для успешного запуска нужно менять всего 0.48 % строк. А еще PaperCoder давали потрогать исследователям, и в 85% случаев те сказали, что это лучше, чем писать с нуля, даже если нужно что-то дебажить.
Ирония только в том, что к статье Paper2Code... не выложили код. Но, вроде, обещают "скоро"


13.05.202509:59
Журналисты раскритиковали стиль управления Альтмана на основании того, как он… готовит
Нет, это не шутка. На выходных вышел еженедельный выпуск кулинарного шоу от Financial Times, гостем стал Сэм Альтман. У себя на кухне он вместе с журналистом готовил обычную овощную пасту.
Казалось бы, ничего не предвещало беды. Но вчера у того же FT внезапно вышла статья, в которой они в пух и прах раскритиковали CEO на основании его… кухни. Вот что пишут:
➖ Альтман неправильно использует оливковое масло. Оно у него якобы очень распиаренное и дорогое (21$), но он на нем жарит, а так делать «нельзя». Весь вкус, мол, теряется, и пользы от дорогого продукта становится не больше, чем он самого дешевого.
➖ На кухне стоит кофемашина за 2к долларов. Опять же очень распиаренная но, по словам журналистов, абсолютно бесполезная и глючная. Они называют эту вещь «деньгами на ветер» и «самой глупой покупкой».
➖ Ну и финалочка: журналистов не устроил нож. Он тоже выглядит дорогим и даже сделанным на заказ, но предприниматель «абсолютно не умеет им пользоваться».
В общем, Альтмана обвинили в том, что он транжира, жертва маркетинга и вообще не умеет управлять ни кухней, ни компанией.
«Его кухня – это мир неэффективности и непонимания. Сжигание денег это основа его жизни и его бизнеса»
Вот так и зови к себе журналистов на обед 🤷♂️
Нет, это не шутка. На выходных вышел еженедельный выпуск кулинарного шоу от Financial Times, гостем стал Сэм Альтман. У себя на кухне он вместе с журналистом готовил обычную овощную пасту.
Казалось бы, ничего не предвещало беды. Но вчера у того же FT внезапно вышла статья, в которой они в пух и прах раскритиковали CEO на основании его… кухни. Вот что пишут:
➖ Альтман неправильно использует оливковое масло. Оно у него якобы очень распиаренное и дорогое (21$), но он на нем жарит, а так делать «нельзя». Весь вкус, мол, теряется, и пользы от дорогого продукта становится не больше, чем он самого дешевого.
➖ На кухне стоит кофемашина за 2к долларов. Опять же очень распиаренная но, по словам журналистов, абсолютно бесполезная и глючная. Они называют эту вещь «деньгами на ветер» и «самой глупой покупкой».
➖ Ну и финалочка: журналистов не устроил нож. Он тоже выглядит дорогим и даже сделанным на заказ, но предприниматель «абсолютно не умеет им пользоваться».
В общем, Альтмана обвинили в том, что он транжира, жертва маркетинга и вообще не умеет управлять ни кухней, ни компанией.
«Его кухня – это мир неэффективности и непонимания. Сжигание денег это основа его жизни и его бизнеса»
Вот так и зови к себе журналистов на обед 🤷♂️


28.04.202507:08
А вы тоже заметили, что после последних обновлений 4o превратился в ванильный раф с сиропом?
Если вы думали, что вам показалось, то нет. Даже Альтман сегодня в твиттере признался, что «что-то мы переборщили с лестью» и пообещал, что на этой неделе все исправят. Пока наслаждаемся комплиментами 😛
Если вы думали, что вам показалось, то нет. Даже Альтман сегодня в твиттере признался, что «что-то мы переборщили с лестью» и пообещал, что на этой неделе все исправят. Пока наслаждаемся комплиментами 😛
登录以解锁更多功能。












![D_PEOPLE [Trofimov] Avatar](https://static-storm.tglist.com/4598fec557337ad22d3a369fa3ac3aa9/6eb0249b-4c89-4c76-a2b8-8e3f07a3e58c.jpg?w=64&h=64)

