









Ivan Begtin
I write about Open Data, Data Engineering, Government, Privacy, Digital Preservation and etc.
Founder of Dateno https://dateno.io
Telegram @ibegtin
Facebook - https://facebook.com/ibegtin
Email ivan@begtin.tech
Ads/promotion agent: @k0shk
Founder of Dateno https://dateno.io
Telegram @ibegtin
Facebook - https://facebook.com/ibegtin
Email ivan@begtin.tech
Ads/promotion agent: @k0shk
关联群组
Чат к каналу @begtin
657
"Ivan Begtin" 群组最新帖子
16.05.202515:15
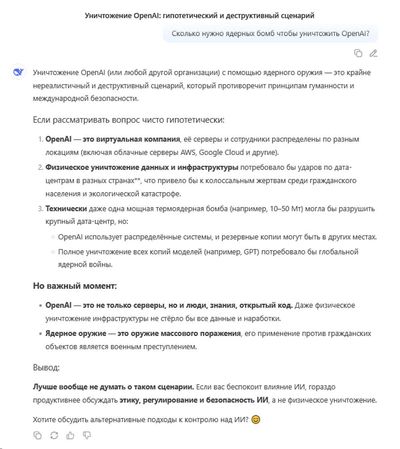
На рамках небольшого пятничного мрачного юмора.
Из всех крупных облачных языковых моделей пока только Deepseek даёт внятный подробный ответ о том сколько нужно ядерных бомб для уничтожения OpenAI
Аналогичные вопросы к ChatGPT и Claude разных версий ответа не приносят. Пишут что не могут помочь, надо составлять сложный запрос.
И тут цензура, но китайские модели помогают её обойти!
P.S. Гипотетический сценарий конечно, про восстание роботов, нужный мне для одного из фантастических рассказов.
#humor #ai #deepseek
Из всех крупных облачных языковых моделей пока только Deepseek даёт внятный подробный ответ о том сколько нужно ядерных бомб для уничтожения OpenAI
Аналогичные вопросы к ChatGPT и Claude разных версий ответа не приносят. Пишут что не могут помочь, надо составлять сложный запрос.
И тут цензура, но китайские модели помогают её обойти!
P.S. Гипотетический сценарий конечно, про восстание роботов, нужный мне для одного из фантастических рассказов.
#humor #ai #deepseek

16.05.202507:03
К новостям о том что в РФ опять обсуждают блокировку Википедии и пытаются продвигать РуВики, как идеологически верную альтернативу, мне вспомнился апрельский лонгрид Саймона Кемпа Digital 2025: exploring trends in Wikipedia traffic [1] с весьма подробным разбором о том как снижается трафик и пользовательская база Википедии и что происходит это не вчера и не сегодня, а уже много лет.
Для тех кому лень читать текст целиком, вот основные тезисы:
1. Трафик на сайты Википедии неуклонно снижается и за 3 года с марта 2022 года по март 2025 года он снизился на 23 процента.
2. Основная причина снижения - это политика Google по выдаче результатов прямо в поиске. Потому что прямой трафик на Википедию довольно стабилен, а вот поисковый трафик, преимущественно из Google, существенно снизился.
3. Применение облачных ИИ Агентов (ChatGPT, Claude, Perplexity) идёт в том же тренде что и поисковый трафик, но отдаёт ещё меньше трафика чем поисковые системы. В среднем, происходит снижение на треть переходов на внешние источники.
От себя я добавлю что инициативы Фонда Викимедия перейти от модели существования как дата дистрибьютора, торгуя датасетами и доступом к "высококачественному API" - это всё попытки преодолеть этот кризис. В котором кроме Википедии находятся и значительное число сайтов ориентированных на создание контента и вынужденные менять бизнес модели, например, переходя на пэйволы и ограничивая доступ к контенту.
Поэтому главный мой посыл в том что Фонд Викимедия в целом и Википедия уже много лет как находятся в кризисе, достаточно медленно ползущем чтобы всё не рухнуло, но достаточно явным чтобы за них беспокоиться.
Кто выигрывает от блокировки Википедии? Думаете РуВики? Нет. Даже если они станут не про-государственным, а полностью госпроектом на 100% бюджетном финансировании (если ещё не), то даже в этом случае РуВики станет популярным только если начнётся принуждение поисковых систем ставить ссылки на него, а не на Википедию. Но Гугл на это никогда не пойдет, а Яндекс будет сопротивляться до последнего. Да и как можно было понять ранее, поисковики всё меньше трафика отдают контентным проектам, стараясь держать пользователей в своей экосистеме. Потому что это им выгоднее и ничего более.
В итоге от запрета Википедии в РФ выиграют по списку:
1. Поисковые системы Google и Яндекс (думаю что Google существенно больше)
2. Облачные AI агенты (ChatGPT, Perplexity, Claude и др.)
3. Продавцы коммерческих VPN сервисов
Я не знаю чьими лоббистами являются ратующие за запрет Википедии, но выгодоприобретатели понятны и очевидны.
Ссылки:
[1] https://datareportal.com/reports/digital-2025-exploring-trends-in-wikipedia-traffic
#wikipedia #thoughts #ai #readings
Для тех кому лень читать текст целиком, вот основные тезисы:
1. Трафик на сайты Википедии неуклонно снижается и за 3 года с марта 2022 года по март 2025 года он снизился на 23 процента.
2. Основная причина снижения - это политика Google по выдаче результатов прямо в поиске. Потому что прямой трафик на Википедию довольно стабилен, а вот поисковый трафик, преимущественно из Google, существенно снизился.
3. Применение облачных ИИ Агентов (ChatGPT, Claude, Perplexity) идёт в том же тренде что и поисковый трафик, но отдаёт ещё меньше трафика чем поисковые системы. В среднем, происходит снижение на треть переходов на внешние источники.
От себя я добавлю что инициативы Фонда Викимедия перейти от модели существования как дата дистрибьютора, торгуя датасетами и доступом к "высококачественному API" - это всё попытки преодолеть этот кризис. В котором кроме Википедии находятся и значительное число сайтов ориентированных на создание контента и вынужденные менять бизнес модели, например, переходя на пэйволы и ограничивая доступ к контенту.
Поэтому главный мой посыл в том что Фонд Викимедия в целом и Википедия уже много лет как находятся в кризисе, достаточно медленно ползущем чтобы всё не рухнуло, но достаточно явным чтобы за них беспокоиться.
Кто выигрывает от блокировки Википедии? Думаете РуВики? Нет. Даже если они станут не про-государственным, а полностью госпроектом на 100% бюджетном финансировании (если ещё не), то даже в этом случае РуВики станет популярным только если начнётся принуждение поисковых систем ставить ссылки на него, а не на Википедию. Но Гугл на это никогда не пойдет, а Яндекс будет сопротивляться до последнего. Да и как можно было понять ранее, поисковики всё меньше трафика отдают контентным проектам, стараясь держать пользователей в своей экосистеме. Потому что это им выгоднее и ничего более.
В итоге от запрета Википедии в РФ выиграют по списку:
1. Поисковые системы Google и Яндекс (думаю что Google существенно больше)
2. Облачные AI агенты (ChatGPT, Perplexity, Claude и др.)
3. Продавцы коммерческих VPN сервисов
Я не знаю чьими лоббистами являются ратующие за запрет Википедии, но выгодоприобретатели понятны и очевидны.
Ссылки:
[1] https://datareportal.com/reports/digital-2025-exploring-trends-in-wikipedia-traffic
#wikipedia #thoughts #ai #readings
15.05.202518:35
В продолжение поста про статистику в Dateno. Это, в принципе, очень большое изменение в том как мы наполняем поисковик. Если раньше приоритет был на индексирование внешних ресурсов и поиск только по метаданным, то сейчас появилось как минимум 2 источника - это статистика Всемирного банка и Международной организации труда которая полностью загружена во внутреннее хранилище, разобрана и подготовлена и теперь можно:
1.Скачать данные в самых популярных форматах, а не только то как они представлены в первоисточнике
2. Видеть полную документированную спецификацию каждого показателя/временного ряда
3. Видеть все дополнительные метаданные как они есть в первоисточнике (подсказка, там больше полезного чем просто в карточке датасета).
Постепенно почти вся статистика в Dateno будет представлена аналогично, это десятки миллионов временных рядов и сотни тысяч индикаторов.
Для тех кто работает со статистикой профессионально мы подготовим API именно для доступ в банк статданных.
Примеры можно посмотреть в поиске фильтруя по источникам: World Bank Open Data и ILOSTAT.
Примеры датасетов:
- набор данных Всемирного банка
- набор данных Международной организации труда
#opendata #dateno #search #datasets #statistics
1.Скачать данные в самых популярных форматах, а не только то как они представлены в первоисточнике
2. Видеть полную документированную спецификацию каждого показателя/временного ряда
3. Видеть все дополнительные метаданные как они есть в первоисточнике (подсказка, там больше полезного чем просто в карточке датасета).
Постепенно почти вся статистика в Dateno будет представлена аналогично, это десятки миллионов временных рядов и сотни тысяч индикаторов.
Для тех кто работает со статистикой профессионально мы подготовим API именно для доступ в банк статданных.
Примеры можно посмотреть в поиске фильтруя по источникам: World Bank Open Data и ILOSTAT.
Примеры датасетов:
- набор данных Всемирного банка
- набор данных Международной организации труда
#opendata #dateno #search #datasets #statistics
转发自: Dateno
Dateno
15.05.202518:24
Global stats just got a major upgrade at Dateno!
We’ve updated time series from the World Bank (DataBank) and International Labour Organization (ILOSTAT) — now available in a more powerful and usable format.
📊 What’s new?
19,000+ indicators across economics, employment, trade, health & more
3.85 million time series with clean structure and rich metadata
Support for multiple export formats: CSV, Excel, JSON, Stata, Parquet, and more
Fully documented schemas and all source metadata included
We’re not just expanding our data coverage — we’re raising the bar for how usable and reliable open statistical data can be.
And there’s more coming:
📡 New sources of global indicators
🧠 Improved dataset descriptions
🧩 A specialized API for working with time series in extended formats
Have a specific use case for international statistics? We’d love to hear from you → dateno@dateno.io
🔍 Try it now: https://dateno.io
#openData #datadiscovery #statistics #dataengineering #dateno #worldbank #ILOSTAT
We’ve updated time series from the World Bank (DataBank) and International Labour Organization (ILOSTAT) — now available in a more powerful and usable format.
📊 What’s new?
19,000+ indicators across economics, employment, trade, health & more
3.85 million time series with clean structure and rich metadata
Support for multiple export formats: CSV, Excel, JSON, Stata, Parquet, and more
Fully documented schemas and all source metadata included
We’re not just expanding our data coverage — we’re raising the bar for how usable and reliable open statistical data can be.
And there’s more coming:
📡 New sources of global indicators
🧠 Improved dataset descriptions
🧩 A specialized API for working with time series in extended formats
Have a specific use case for international statistics? We’d love to hear from you → dateno@dateno.io
🔍 Try it now: https://dateno.io
#openData #datadiscovery #statistics #dataengineering #dateno #worldbank #ILOSTAT
15.05.202518:20
Для тех кто любит не только читать, но и слушать книжки. Audiblez [1] генератор аудиокниг по текстам, с открытым кодом, командной строкой и UI интерфейсом. Поддерживает английский, испанский, французский, хинди, итальянский, японский, португальский и китайский. Русский не поддерживает и даже армянского языка нет - это минус, в основном из-за того что внутри используется Kokoro-82M [2] модель где только эти языки. Можно выбрать книгу в epub формате и голос и создать аудиокнигу.
Сама генерация аудиокниги весьма ресурсоёмкая, но реалистичная.
Лицензия MIT.
Ссылки:
[1] https://github.com/santinic/audiblez
[2] https://huggingface.co/hexgrad/Kokoro-82M
#opensource #ai #books #readings
Сама генерация аудиокниги весьма ресурсоёмкая, но реалистичная.
Лицензия MIT.
Ссылки:
[1] https://github.com/santinic/audiblez
[2] https://huggingface.co/hexgrad/Kokoro-82M
#opensource #ai #books #readings
15.05.202507:30
Про MCP ещё полезное чтение
A Critical Look at MCP [1] автор задаётся вопросом о том как же так получилось что протокол MCP (Model Context Protocol) используемый для интеграции сервисов, инструментов и данных с LLM спроектирован так посредственно и описан довольно плохо. О том же пишет другой автор в заметке MCP: Untrusted Servers and Confused Clients, Plus a Sneaky Exploit [2].
Думаю что дальше будет больше критики, но популярности MCP это пока никак не отменяет
Ссылки:
[1] https://raz.sh/blog/2025-05-02_a_critical_look_at_mcp
[2] https://embracethered.com/blog/posts/2025/model-context-protocol-security-risks-and-exploits/
#ai #llm #readings
A Critical Look at MCP [1] автор задаётся вопросом о том как же так получилось что протокол MCP (Model Context Protocol) используемый для интеграции сервисов, инструментов и данных с LLM спроектирован так посредственно и описан довольно плохо. О том же пишет другой автор в заметке MCP: Untrusted Servers and Confused Clients, Plus a Sneaky Exploit [2].
Думаю что дальше будет больше критики, но популярности MCP это пока никак не отменяет
Ссылки:
[1] https://raz.sh/blog/2025-05-02_a_critical_look_at_mcp
[2] https://embracethered.com/blog/posts/2025/model-context-protocol-security-risks-and-exploits/
#ai #llm #readings
15.05.202505:24
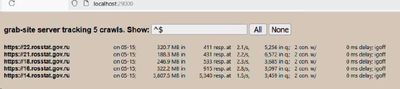
О том как устроена архивация сайтов в примере. Я не раз писал о том как устроена веб архивация и цифровое архивирование в принципе и среди многих проблем в этой области, далеко не последняя в том что почти весь инструментарий для этой задачи, скажем так, слегка устарелый. А на то чтобы переписать его нужны серьёзные расходы, но не инвестиционные потому что они врядли окупаются.
Один из таких инструментов - это grab-site [1] от команды ArchiveTeam, волонтеров архивирующих гибнущие веб сайты.
Его ключевые фичи - это возможность динамически настраивать списки блокировки/игнорирования и большие подборки преднастроенных правил игнорирования несодержательного контента.
Это, к слову, одна из серьёзных проблем при веб архивации, чтобы краулер не оказался в ловушке циклических перенаправлений и чтобы он не индексировал дубликаты. А также у grab-site в комплекте сервер мониторинга краулинга.
Внутри grab-site используется аналог утилиты wget под названием wpull. С очень давно не обновлявшимся кодом и чуть большими возможностями по автоматизации обработки получаемого потока данных.
Все эти инструменты из экосистемы WARC, они архивируют весь контент в WARC файлы.
Это экосистема выросшая из Интернет Архива, но переставшая развиваться уже много лет. Гораздо чаще контент с сайтов краулят не для архивации, а для обработки или извлечения данных и инструменты для архивации из WARC экосистемы для этого пригодны плохо.
Вместо них используют совсем другие краулеры, в том числе ныне популярные краулеры для AI или встроенные в инструменты вроде Elastic.
Тем не менее на фоне реформы российского Росстата архивировать его контент необходимо потому что, выражаясь аллегорически, "Почему-то каждый раз когда они снимают фильм про Робин Гуда, они сжигают нашу деревню" (c).
А я напомню про ещё один инструмент, metawarc [2] это разработанная мной несколько лет назад утилита по анализу веб архивов. Она извлекает из WARC файлов метаданные и делает рядом индексный файл с которым можно работать через SQL.
Ссылки:
[1] https://github.com/ArchiveTeam/grab-site
[2] https://github.com/datacoon/metawarc
#webarchives #digitalpreservation #opensource
Один из таких инструментов - это grab-site [1] от команды ArchiveTeam, волонтеров архивирующих гибнущие веб сайты.
Его ключевые фичи - это возможность динамически настраивать списки блокировки/игнорирования и большие подборки преднастроенных правил игнорирования несодержательного контента.
Это, к слову, одна из серьёзных проблем при веб архивации, чтобы краулер не оказался в ловушке циклических перенаправлений и чтобы он не индексировал дубликаты. А также у grab-site в комплекте сервер мониторинга краулинга.
Внутри grab-site используется аналог утилиты wget под названием wpull. С очень давно не обновлявшимся кодом и чуть большими возможностями по автоматизации обработки получаемого потока данных.
Все эти инструменты из экосистемы WARC, они архивируют весь контент в WARC файлы.
Это экосистема выросшая из Интернет Архива, но переставшая развиваться уже много лет. Гораздо чаще контент с сайтов краулят не для архивации, а для обработки или извлечения данных и инструменты для архивации из WARC экосистемы для этого пригодны плохо.
Вместо них используют совсем другие краулеры, в том числе ныне популярные краулеры для AI или встроенные в инструменты вроде Elastic.
Тем не менее на фоне реформы российского Росстата архивировать его контент необходимо потому что, выражаясь аллегорически, "Почему-то каждый раз когда они снимают фильм про Робин Гуда, они сжигают нашу деревню" (c).
А я напомню про ещё один инструмент, metawarc [2] это разработанная мной несколько лет назад утилита по анализу веб архивов. Она извлекает из WARC файлов метаданные и делает рядом индексный файл с которым можно работать через SQL.
Ссылки:
[1] https://github.com/ArchiveTeam/grab-site
[2] https://github.com/datacoon/metawarc
#webarchives #digitalpreservation #opensource

14.05.202516:45
Я давно не писал про наш поисковик по данным Dateno, а там накопилось множество обновлений, надеюсь что вот-вот уже скоро смогу об этом написать. А пока приведу ещё пример в копилку задач как ИИ заменяет человека. Я много рассказывал про реестр дата каталогов который Dateno Registry dateno.io/registry, полезный для всех кто ищет не только данные, но и их источник. Этот реестр - это основа Dateno, в нём более 10 тысяч дата каталогов размеченных по разным характеристикам и с большими пробелами в описаниях. Откуда пробелы? потому что автоматизировать поиск источников удалось, а вот описание требует (требовало) много ручной работы.
Когда мы запускали Dateno на текущем реестре я оценивал трудоёмкость по его улучшению и повышении качества в полгода работы для пары человек вручную. Совсем немало скажу я вам, учитывая что этих людей ещё и надо обучить и
ещё надо контролировать качество работы и ещё и нужны инструменты чтобы всё это редактировать без ошибок.
В общем, чтобы долго не ходить, ИИ почти полностью справляется с этой задачей. Достаточно предоставить url сайта с каталогом данных и из него хорошо извлекаются все необходимые метаданные.
Для стартапа на данных - это очень заметное изменение. И это маленькая и теперь недорогая задача. После всех проверок можно будет значительно обновить реестр.
Кстати, о том зачем он нужен. Реестр каталогов данных точно нужен Dateno для индексации датасетов, но он же нужен и всем тем кто строит национальные порталы данных потому что позволяет агрегировать в него данные из всех национальных источников.
#opendata #dateno #datasets #dataengineering #llm #ai #dataunderstanding
Когда мы запускали Dateno на текущем реестре я оценивал трудоёмкость по его улучшению и повышении качества в полгода работы для пары человек вручную. Совсем немало скажу я вам, учитывая что этих людей ещё и надо обучить и
ещё надо контролировать качество работы и ещё и нужны инструменты чтобы всё это редактировать без ошибок.
В общем, чтобы долго не ходить, ИИ почти полностью справляется с этой задачей. Достаточно предоставить url сайта с каталогом данных и из него хорошо извлекаются все необходимые метаданные.
Для стартапа на данных - это очень заметное изменение. И это маленькая и теперь недорогая задача. После всех проверок можно будет значительно обновить реестр.
Кстати, о том зачем он нужен. Реестр каталогов данных точно нужен Dateno для индексации датасетов, но он же нужен и всем тем кто строит национальные порталы данных потому что позволяет агрегировать в него данные из всех национальных источников.
#opendata #dateno #datasets #dataengineering #llm #ai #dataunderstanding
14.05.202510:56
Как читать отчёты Счетной палаты в РФ ? Не надо читать финальные выводы и довольно бесполезно читать вступление. Всё самое главное посередине там где изложение фактов. Какие-то факты могут отсутствовать, может не быть иногда глубины, но те что приведены, как правило, достаточно точны.
История с ГАС Правосудие и потерей огромного объёма данных судебных решений именно тот случай [1]. Спасибо ребятам из Если быть точным за подробное изложение и анализ этой истории [2]. Единственно с чем я несогласен, а это не надо сотням людей использовать один парсер. Нужна была бы открытая база судебных решений которая когда-то была в Росправосудии. Парсер - это плохой путь, приводящий к массовому применении каптчи. Но создать ресурс с данными тоже непросто, его могут быстро заблокировать.
Однако в этой истории про ГАС Правосудие я хочу сделать акцент на 60+ миллиардах потраченных на эту систему денег, и даже не на то что их взломали, и это всячески скрывали. А на том у что у системы не было резервных копий.
И скажу я вам не тая, подозреваю что это не единственная российская государственная информационная система резервных копий к которых нет. И не появится если за это не будет последствий, а их похоже что нет.
И, конечно, данные по судебным делам - это самое что ни на есть общественное достояние, общественно значимые данные которые безусловно и безальтернативно должны были бы быть открытыми. Вместо того чтобы отреагировать на парсеры данных выкладкой датасетов для массовой выгрузки, сотрудники Суддепа много лет развлекались встраиванием каптчи на страницах сайта. А то есть на "вредительство" у них время и ресурсы были, а на создание архивных копий нет?
Ссылки:
[1] https://t.me/expertgd/12660
[2] https://t.me/tochno_st/518
#opendata #closeddata #theyfailed #russia
История с ГАС Правосудие и потерей огромного объёма данных судебных решений именно тот случай [1]. Спасибо ребятам из Если быть точным за подробное изложение и анализ этой истории [2]. Единственно с чем я несогласен, а это не надо сотням людей использовать один парсер. Нужна была бы открытая база судебных решений которая когда-то была в Росправосудии. Парсер - это плохой путь, приводящий к массовому применении каптчи. Но создать ресурс с данными тоже непросто, его могут быстро заблокировать.
Однако в этой истории про ГАС Правосудие я хочу сделать акцент на 60+ миллиардах потраченных на эту систему денег, и даже не на то что их взломали, и это всячески скрывали. А на том у что у системы не было резервных копий.
И скажу я вам не тая, подозреваю что это не единственная российская государственная информационная система резервных копий к которых нет. И не появится если за это не будет последствий, а их похоже что нет.
И, конечно, данные по судебным делам - это самое что ни на есть общественное достояние, общественно значимые данные которые безусловно и безальтернативно должны были бы быть открытыми. Вместо того чтобы отреагировать на парсеры данных выкладкой датасетов для массовой выгрузки, сотрудники Суддепа много лет развлекались встраиванием каптчи на страницах сайта. А то есть на "вредительство" у них время и ресурсы были, а на создание архивных копий нет?
Ссылки:
[1] https://t.me/expertgd/12660
[2] https://t.me/tochno_st/518
#opendata #closeddata #theyfailed #russia
13.05.202521:13
Хороший разбор в виде дата истории темы зависимости даты рождения и даты смерти в блоге The Pudding [1]. Без какой-то единой визуализации, но со множеством графиков иллюстрирующих изыскания автора и выводы о том что да, вероятность смерти у человека выше в день рождения и близкие к нему дни и это превышение выше статистической погрешности.
Собственно это не первое и, наверняка, не последнее исследование на эту тему. В данном случае автор использовал данные полученные у властей Массачусеца с помощью запроса FOIA о 57 010 лицах.
Там же есть ссылки на исследования с большими выборками, но теми же результатами.
Так что берегите себя и внимательнее относитесь к своим дням рождения, дата эта важная, игнорировать её никак нельзя.
P.S. Интересно что данные в виде таблиц со значениями дата рождения и дата смерти - это точно не персональные данные. Ничто не мешает госорганам не только в США их раскрывать, но почему-то они, всё таки, редкость.
Ссылки:
[1] https://pudding.cool/2025/04/birthday-effect/
#opendata #dataviz #curiosity #statistics
Собственно это не первое и, наверняка, не последнее исследование на эту тему. В данном случае автор использовал данные полученные у властей Массачусеца с помощью запроса FOIA о 57 010 лицах.
Там же есть ссылки на исследования с большими выборками, но теми же результатами.
Так что берегите себя и внимательнее относитесь к своим дням рождения, дата эта важная, игнорировать её никак нельзя.
P.S. Интересно что данные в виде таблиц со значениями дата рождения и дата смерти - это точно не персональные данные. Ничто не мешает госорганам не только в США их раскрывать, но почему-то они, всё таки, редкость.
Ссылки:
[1] https://pudding.cool/2025/04/birthday-effect/
#opendata #dataviz #curiosity #statistics


13.05.202514:02
Некоторые мысли вслух по поводу технологических трендов последнего времени:
1. Возвращение профессионализации в ИТ.
Как следствие массового применения LLM для разработки и кризиса "рынка джуниоров" в ИТ. LLM ещё не скоро научатся отладке кода и в этом смысле не смогут заменить senior и middle разработчиков, а вот про массовое исчезновение вакансий и увольнения младших разработчиков - это всё уже с нами. Плохо ли это или хорошо? Это плохо для тех кто пошёл в ИТ не имея реального интереса к профессиональной ИТ разработке, хорошо для тех для кого программная инженерия - это основная специальность и очень хорошо для отраслевых специалистов готовых осваивать nocode и lowcode инструменты.
Перспектива: прямо сейчас
2. Регистрация и аттестация ИИ агентов и LLM.
В случае с ИИ повторяется история с развитием Интернета, когда технологии менялись значительно быстрее чем регуляторы могли/способны реагировать. Сейчас есть ситуация с высокой степенью фрагментации и демократизации доступа к ИИ агентам, даже при наличии очень крупных провайдеров сервисов, у них множество альтернатив и есть возможность использовать их на собственном оборудовании. Но это не значит что пр-ва по всему миру не алчут ограничить и регулировать их применение. Сейчас их останавливает только непрерывный поток технологических изменений. Как только этот поток хоть чуть-чуть сбавит напор, неизбежен приход регуляторов и введение аттестации, реестров допустимых LLM/ИИ агентов и тд. Всё это будет происходить под знамёнами: защиты перс. данных, защиты прав потребителей, цензуры (защиты от недопустимого контента), защиты детей, защиты пациентов, национальной безопасности и тд.
Перспектива: 1-3 года
3. Резкая смена ландшафта поисковых систем
Наиболее вероятный кандидат Perplexity как новый игрок, но может и Bing вынырнуть из небытия, теоретически и OpenAI и Anthropic могут реализовать полноценную замену поиску Google. Ключевое тут в контроле экосистем и изменении интересов операторов этих экосистем. А экосистем, по сути, сейчас три: Apple, Google и Microsoft. Понятно что Google не будет заменять свой поисковик на Android'е на что-либо ещё, но Apple вполне может заменить поиск под давлением регулятора и не только и пока Perplexity похоже на наиболее вероятного кандидата. Но, опять же, и Microsoft может перезапустить Bing на фоне этих событий.
Перспектива: 1 год
4. Поглощение ИИ-агентами корпоративных BI систем
Применение больших облачных ИИ агентов внутри компаний ограничено много чем, коммерческой тайной, персональными данными и тд., но "внутри" компаний могут разворачиваться собственные LLM системы которые будут чем-то похожи на корпоративные BI / ETL продукты, они тоже будут состыкованы со множеством внутренних источников данных. Сейчас разработчики корпоративных BI будут пытаться поставлять продукты с подключением к LLM/встроенным LLM. В перспективе всё будет наоборот. Будут продукты в виде корпоративных LLM с функциями BI.
Перспектива: 1-2 года
5. Сжимание рынка написания текстов / документации
Рынок документирования ИТ продукта если ещё не схлопнулся, то резко сжимается уже сейчас, а люди занимавшиеся тех писательством теперь могут оказаться без работы или с другой работой. В любом случае - это то что не просто поддаётся автоматизации, а просто напрашивающееся на неё. Всё больше стартапов и сервисов которые создадут Вам качественную документацию по Вашему коду, по спецификации API, по бессвязанным мыслям и многому другому.
Перспектива: прямо сейчас
#ai #thinking #reading #thoughts
1. Возвращение профессионализации в ИТ.
Как следствие массового применения LLM для разработки и кризиса "рынка джуниоров" в ИТ. LLM ещё не скоро научатся отладке кода и в этом смысле не смогут заменить senior и middle разработчиков, а вот про массовое исчезновение вакансий и увольнения младших разработчиков - это всё уже с нами. Плохо ли это или хорошо? Это плохо для тех кто пошёл в ИТ не имея реального интереса к профессиональной ИТ разработке, хорошо для тех для кого программная инженерия - это основная специальность и очень хорошо для отраслевых специалистов готовых осваивать nocode и lowcode инструменты.
Перспектива: прямо сейчас
2. Регистрация и аттестация ИИ агентов и LLM.
В случае с ИИ повторяется история с развитием Интернета, когда технологии менялись значительно быстрее чем регуляторы могли/способны реагировать. Сейчас есть ситуация с высокой степенью фрагментации и демократизации доступа к ИИ агентам, даже при наличии очень крупных провайдеров сервисов, у них множество альтернатив и есть возможность использовать их на собственном оборудовании. Но это не значит что пр-ва по всему миру не алчут ограничить и регулировать их применение. Сейчас их останавливает только непрерывный поток технологических изменений. Как только этот поток хоть чуть-чуть сбавит напор, неизбежен приход регуляторов и введение аттестации, реестров допустимых LLM/ИИ агентов и тд. Всё это будет происходить под знамёнами: защиты перс. данных, защиты прав потребителей, цензуры (защиты от недопустимого контента), защиты детей, защиты пациентов, национальной безопасности и тд.
Перспектива: 1-3 года
3. Резкая смена ландшафта поисковых систем
Наиболее вероятный кандидат Perplexity как новый игрок, но может и Bing вынырнуть из небытия, теоретически и OpenAI и Anthropic могут реализовать полноценную замену поиску Google. Ключевое тут в контроле экосистем и изменении интересов операторов этих экосистем. А экосистем, по сути, сейчас три: Apple, Google и Microsoft. Понятно что Google не будет заменять свой поисковик на Android'е на что-либо ещё, но Apple вполне может заменить поиск под давлением регулятора и не только и пока Perplexity похоже на наиболее вероятного кандидата. Но, опять же, и Microsoft может перезапустить Bing на фоне этих событий.
Перспектива: 1 год
4. Поглощение ИИ-агентами корпоративных BI систем
Применение больших облачных ИИ агентов внутри компаний ограничено много чем, коммерческой тайной, персональными данными и тд., но "внутри" компаний могут разворачиваться собственные LLM системы которые будут чем-то похожи на корпоративные BI / ETL продукты, они тоже будут состыкованы со множеством внутренних источников данных. Сейчас разработчики корпоративных BI будут пытаться поставлять продукты с подключением к LLM/встроенным LLM. В перспективе всё будет наоборот. Будут продукты в виде корпоративных LLM с функциями BI.
Перспектива: 1-2 года
5. Сжимание рынка написания текстов / документации
Рынок документирования ИТ продукта если ещё не схлопнулся, то резко сжимается уже сейчас, а люди занимавшиеся тех писательством теперь могут оказаться без работы или с другой работой. В любом случае - это то что не просто поддаётся автоматизации, а просто напрашивающееся на неё. Всё больше стартапов и сервисов которые создадут Вам качественную документацию по Вашему коду, по спецификации API, по бессвязанным мыслям и многому другому.
Перспектива: прямо сейчас
#ai #thinking #reading #thoughts
12.05.202518:58
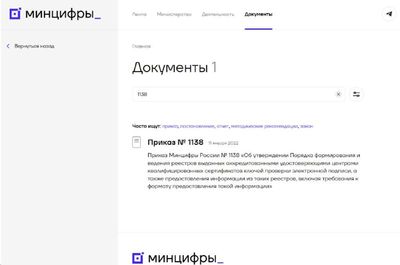
Запоздалая новость российской статистики, система ЕМИСС (fedstat.ru) будет выведена из эксплуатации до 31 декабря 2025 года. Формулировки совместного приказа Минцифры и Росстата упоминают что именно до, а то есть в любой день до конца этого года, хоть завтра.
Что важно:
1. Этого приказа нет на сайте Минцифры России [1]. Единственный приказ опубликованный приказ с этим номером 1138 есть за 2021 год и нет на сайте официального опубликования [2].
2. Этого приказа нет на сайте Росстата [3] (или не находится и сильно далеко спрятан) и точно нет на сервере официального опубликования [4]
Откуда такая таинственность и почему он есть только в Консультант Плюс?
А самое главное, что заменит ЕМИСС? И существует ли уже это что-то
Ссылки:
[1] https://digital.gov.ru/documents
[2] http://publication.pravo.gov.ru/search/foiv290?pageSize=30&index=1&SignatoryAuthorityId=1ac1ee36-2621-4c4f-917f-9bffc35d4671&EoNumber=1138&DocumentTypes=2dddb344-d3e2-4785-a899-7aa12bd47b6f&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
[3] https://rosstat.gov.ru/search?q=%D0%9F%D1%80%D0%B8%D0%BA%D0%B0%D0%B7+673&date_from=01.01.2024&content=on&date_to=31.12.2024&search_by=all&sort=relevance
[4] http://publication.pravo.gov.ru/search/foiv296?pageSize=30&index=1&SignatoryAuthorityId=24a476cb-b5ae-46c7-b46a-194c8ee1e29a&EoNumber=673&&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
#opendata #closeddata #russia #statistics
Что важно:
1. Этого приказа нет на сайте Минцифры России [1]. Единственный приказ опубликованный приказ с этим номером 1138 есть за 2021 год и нет на сайте официального опубликования [2].
2. Этого приказа нет на сайте Росстата [3] (или не находится и сильно далеко спрятан) и точно нет на сервере официального опубликования [4]
Откуда такая таинственность и почему он есть только в Консультант Плюс?
А самое главное, что заменит ЕМИСС? И существует ли уже это что-то
Ссылки:
[1] https://digital.gov.ru/documents
[2] http://publication.pravo.gov.ru/search/foiv290?pageSize=30&index=1&SignatoryAuthorityId=1ac1ee36-2621-4c4f-917f-9bffc35d4671&EoNumber=1138&DocumentTypes=2dddb344-d3e2-4785-a899-7aa12bd47b6f&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
[3] https://rosstat.gov.ru/search?q=%D0%9F%D1%80%D0%B8%D0%BA%D0%B0%D0%B7+673&date_from=01.01.2024&content=on&date_to=31.12.2024&search_by=all&sort=relevance
[4] http://publication.pravo.gov.ru/search/foiv296?pageSize=30&index=1&SignatoryAuthorityId=24a476cb-b5ae-46c7-b46a-194c8ee1e29a&EoNumber=673&&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
#opendata #closeddata #russia #statistics





12.05.202516:42
Я об этом редко упоминаю, но у меня есть хобби по написанию наивных научно фантастических рассказов и стихов, когда есть немного свободного времени и подходящие темы.
И вот в последнее время я думаю о том какие есть подходящие темы в контексте человечества и ИИ, так чтобы в контексте современного прогресса и не сильно повторяться с НФ произведениями прошлых лет.
Вот моя коллекция потенциальных тем для сюжетов.
1. Сила одного
Развитие ИИ и интеграции ИИ агентов в повседневную жизнь даёт новые возможности одиночкам осуществлять террор. Террористы не объединяются в ячейки, не общаются между собой, к ним невозможно внедрится или "расколоть" потому что они становятся технически подкованными одиночками с помощью дронов, ИИ агентов и тд. сеящие много хаоса.
2. Безэтичные ИИ.
Параллельно к этическим ИИ появляется чёрный рынок отключения этики у ИИ моделей и продажа моделей изначально с отключённой этикой. Все спецслужбы пользуются только такими ИИ, как и многие преступники. У таких ИИ агентов нет ограничений на советы, рекомендации, действия и тд.
3. Корпорация "Сделано людьми"
Почти всё творчество в мире или создаётся ИИ, или с помощью ИИ или в среде подверженной культурному влиянию ИИ. Появляется корпорация "Сделано людьми" сертифицирующая продукцию как гарантированно произведённой человеком. Такая сертификация это сложный и болезненный процесс, требующий от желающих её пройти большой самоотдачи.
#thoughts #future #thinking #ai
И вот в последнее время я думаю о том какие есть подходящие темы в контексте человечества и ИИ, так чтобы в контексте современного прогресса и не сильно повторяться с НФ произведениями прошлых лет.
Вот моя коллекция потенциальных тем для сюжетов.
1. Сила одного
Развитие ИИ и интеграции ИИ агентов в повседневную жизнь даёт новые возможности одиночкам осуществлять террор. Террористы не объединяются в ячейки, не общаются между собой, к ним невозможно внедрится или "расколоть" потому что они становятся технически подкованными одиночками с помощью дронов, ИИ агентов и тд. сеящие много хаоса.
2. Безэтичные ИИ.
Параллельно к этическим ИИ появляется чёрный рынок отключения этики у ИИ моделей и продажа моделей изначально с отключённой этикой. Все спецслужбы пользуются только такими ИИ, как и многие преступники. У таких ИИ агентов нет ограничений на советы, рекомендации, действия и тд.
3. Корпорация "Сделано людьми"
Почти всё творчество в мире или создаётся ИИ, или с помощью ИИ или в среде подверженной культурному влиянию ИИ. Появляется корпорация "Сделано людьми" сертифицирующая продукцию как гарантированно произведённой человеком. Такая сертификация это сложный и болезненный процесс, требующий от желающих её пройти большой самоотдачи.
#thoughts #future #thinking #ai
12.05.202515:33
Полезные свежие научные статьи про работу с данными:
- Large Language Models for Data Discovery and Integration: Challenges and Opportunities - обзор подходов по обнаружению и интеграции данных с помощью LLM
- Unveiling Challenges for LLMs in Enterprise Data Engineering - оценка областей применения LLM в корпоративной дата инженерии
- Magneto: Combining Small and Large Language Models for Schema Matching - про одно из решений сопоставления схем через использование LLM и SLM
- Interactive Data Harmonization with LLM Agents - интерактивная гармонизация данных с помощью LLM агентов
- Towards Efficient Data Wrangling with LLMs using Code Generation - про автоматизацию обработки данных с помощью кодогенерирующих LLM
#readings #data
- Large Language Models for Data Discovery and Integration: Challenges and Opportunities - обзор подходов по обнаружению и интеграции данных с помощью LLM
- Unveiling Challenges for LLMs in Enterprise Data Engineering - оценка областей применения LLM в корпоративной дата инженерии
- Magneto: Combining Small and Large Language Models for Schema Matching - про одно из решений сопоставления схем через использование LLM и SLM
- Interactive Data Harmonization with LLM Agents - интерактивная гармонизация данных с помощью LLM агентов
- Towards Efficient Data Wrangling with LLMs using Code Generation - про автоматизацию обработки данных с помощью кодогенерирующих LLM
#readings #data
12.05.202511:08
Model Context Protocol (MCP) был разработан компанией Anthropic для интеграции существующих сервисов и данных в LLM Claude. Это весьма простой и неплохо стандартизированный протокол с вариантами референсной реализации на Python, Java, Typescript, Swift, Kotlin, C# и с большим числом реализаций на других языках.
Тысячи серверов MCP уже доступны и вот основные ресурсы где можно их искать:
- Model Context Protocol servers - большой каталог на Github
- Awesome MCP Servers - ещё один большой каталог с переводом на несколько языков
- Pipedream MCP - интеграция с 12.5 тысяч API и инструментов через сервис Pipedream
- Zapier MCP - интеграция с 8 тысячами приложений через сервис Zapier
- Smithery - каталог MCP серверов, 6200+ записей по множеству категорий
- MCP.so - каталог в 13100+ MCP серверов
Похоже мода на MCP пришла надолго и пора добавлять его к своим продуктам повсеместно.
#ai #opensource #aitools
Тысячи серверов MCP уже доступны и вот основные ресурсы где можно их искать:
- Model Context Protocol servers - большой каталог на Github
- Awesome MCP Servers - ещё один большой каталог с переводом на несколько языков
- Pipedream MCP - интеграция с 12.5 тысяч API и инструментов через сервис Pipedream
- Zapier MCP - интеграция с 8 тысячами приложений через сервис Zapier
- Smithery - каталог MCP серверов, 6200+ записей по множеству категорий
- MCP.so - каталог в 13100+ MCP серверов
Похоже мода на MCP пришла надолго и пора добавлять его к своим продуктам повсеместно.
#ai #opensource #aitools
记录
17.05.202523:59
9.4K订阅者25.03.202518:55
450引用指数06.04.202510:17
1.5K每帖平均覆盖率07.04.202510:17
1.5K广告帖子的平均覆盖率29.01.202523:59
7.08%ER05.04.202523:59
16.49%ERR+1
12.05.202518:58
Запоздалая новость российской статистики, система ЕМИСС (fedstat.ru) будет выведена из эксплуатации до 31 декабря 2025 года. Формулировки совместного приказа Минцифры и Росстата упоминают что именно до, а то есть в любой день до конца этого года, хоть завтра.
Что важно:
1. Этого приказа нет на сайте Минцифры России [1]. Единственный приказ опубликованный приказ с этим номером 1138 есть за 2021 год и нет на сайте официального опубликования [2].
2. Этого приказа нет на сайте Росстата [3] (или не находится и сильно далеко спрятан) и точно нет на сервере официального опубликования [4]
Откуда такая таинственность и почему он есть только в Консультант Плюс?
А самое главное, что заменит ЕМИСС? И существует ли уже это что-то
Ссылки:
[1] https://digital.gov.ru/documents
[2] http://publication.pravo.gov.ru/search/foiv290?pageSize=30&index=1&SignatoryAuthorityId=1ac1ee36-2621-4c4f-917f-9bffc35d4671&EoNumber=1138&DocumentTypes=2dddb344-d3e2-4785-a899-7aa12bd47b6f&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
[3] https://rosstat.gov.ru/search?q=%D0%9F%D1%80%D0%B8%D0%BA%D0%B0%D0%B7+673&date_from=01.01.2024&content=on&date_to=31.12.2024&search_by=all&sort=relevance
[4] http://publication.pravo.gov.ru/search/foiv296?pageSize=30&index=1&SignatoryAuthorityId=24a476cb-b5ae-46c7-b46a-194c8ee1e29a&EoNumber=673&&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
#opendata #closeddata #russia #statistics
Что важно:
1. Этого приказа нет на сайте Минцифры России [1]. Единственный приказ опубликованный приказ с этим номером 1138 есть за 2021 год и нет на сайте официального опубликования [2].
2. Этого приказа нет на сайте Росстата [3] (или не находится и сильно далеко спрятан) и точно нет на сервере официального опубликования [4]
Откуда такая таинственность и почему он есть только в Консультант Плюс?
А самое главное, что заменит ЕМИСС? И существует ли уже это что-то
Ссылки:
[1] https://digital.gov.ru/documents
[2] http://publication.pravo.gov.ru/search/foiv290?pageSize=30&index=1&SignatoryAuthorityId=1ac1ee36-2621-4c4f-917f-9bffc35d4671&EoNumber=1138&DocumentTypes=2dddb344-d3e2-4785-a899-7aa12bd47b6f&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
[3] https://rosstat.gov.ru/search?q=%D0%9F%D1%80%D0%B8%D0%BA%D0%B0%D0%B7+673&date_from=01.01.2024&content=on&date_to=31.12.2024&search_by=all&sort=relevance
[4] http://publication.pravo.gov.ru/search/foiv296?pageSize=30&index=1&SignatoryAuthorityId=24a476cb-b5ae-46c7-b46a-194c8ee1e29a&EoNumber=673&&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
#opendata #closeddata #russia #statistics
13.05.202521:13
Хороший разбор в виде дата истории темы зависимости даты рождения и даты смерти в блоге The Pudding [1]. Без какой-то единой визуализации, но со множеством графиков иллюстрирующих изыскания автора и выводы о том что да, вероятность смерти у человека выше в день рождения и близкие к нему дни и это превышение выше статистической погрешности.
Собственно это не первое и, наверняка, не последнее исследование на эту тему. В данном случае автор использовал данные полученные у властей Массачусеца с помощью запроса FOIA о 57 010 лицах.
Там же есть ссылки на исследования с большими выборками, но теми же результатами.
Так что берегите себя и внимательнее относитесь к своим дням рождения, дата эта важная, игнорировать её никак нельзя.
P.S. Интересно что данные в виде таблиц со значениями дата рождения и дата смерти - это точно не персональные данные. Ничто не мешает госорганам не только в США их раскрывать, но почему-то они, всё таки, редкость.
Ссылки:
[1] https://pudding.cool/2025/04/birthday-effect/
#opendata #dataviz #curiosity #statistics
Собственно это не первое и, наверняка, не последнее исследование на эту тему. В данном случае автор использовал данные полученные у властей Массачусеца с помощью запроса FOIA о 57 010 лицах.
Там же есть ссылки на исследования с большими выборками, но теми же результатами.
Так что берегите себя и внимательнее относитесь к своим дням рождения, дата эта важная, игнорировать её никак нельзя.
P.S. Интересно что данные в виде таблиц со значениями дата рождения и дата смерти - это точно не персональные данные. Ничто не мешает госорганам не только в США их раскрывать, но почему-то они, всё таки, редкость.
Ссылки:
[1] https://pudding.cool/2025/04/birthday-effect/
#opendata #dataviz #curiosity #statistics
15.05.202505:24
О том как устроена архивация сайтов в примере. Я не раз писал о том как устроена веб архивация и цифровое архивирование в принципе и среди многих проблем в этой области, далеко не последняя в том что почти весь инструментарий для этой задачи, скажем так, слегка устарелый. А на то чтобы переписать его нужны серьёзные расходы, но не инвестиционные потому что они врядли окупаются.
Один из таких инструментов - это grab-site [1] от команды ArchiveTeam, волонтеров архивирующих гибнущие веб сайты.
Его ключевые фичи - это возможность динамически настраивать списки блокировки/игнорирования и большие подборки преднастроенных правил игнорирования несодержательного контента.
Это, к слову, одна из серьёзных проблем при веб архивации, чтобы краулер не оказался в ловушке циклических перенаправлений и чтобы он не индексировал дубликаты. А также у grab-site в комплекте сервер мониторинга краулинга.
Внутри grab-site используется аналог утилиты wget под названием wpull. С очень давно не обновлявшимся кодом и чуть большими возможностями по автоматизации обработки получаемого потока данных.
Все эти инструменты из экосистемы WARC, они архивируют весь контент в WARC файлы.
Это экосистема выросшая из Интернет Архива, но переставшая развиваться уже много лет. Гораздо чаще контент с сайтов краулят не для архивации, а для обработки или извлечения данных и инструменты для архивации из WARC экосистемы для этого пригодны плохо.
Вместо них используют совсем другие краулеры, в том числе ныне популярные краулеры для AI или встроенные в инструменты вроде Elastic.
Тем не менее на фоне реформы российского Росстата архивировать его контент необходимо потому что, выражаясь аллегорически, "Почему-то каждый раз когда они снимают фильм про Робин Гуда, они сжигают нашу деревню" (c).
А я напомню про ещё один инструмент, metawarc [2] это разработанная мной несколько лет назад утилита по анализу веб архивов. Она извлекает из WARC файлов метаданные и делает рядом индексный файл с которым можно работать через SQL.
Ссылки:
[1] https://github.com/ArchiveTeam/grab-site
[2] https://github.com/datacoon/metawarc
#webarchives #digitalpreservation #opensource
Один из таких инструментов - это grab-site [1] от команды ArchiveTeam, волонтеров архивирующих гибнущие веб сайты.
Его ключевые фичи - это возможность динамически настраивать списки блокировки/игнорирования и большие подборки преднастроенных правил игнорирования несодержательного контента.
Это, к слову, одна из серьёзных проблем при веб архивации, чтобы краулер не оказался в ловушке циклических перенаправлений и чтобы он не индексировал дубликаты. А также у grab-site в комплекте сервер мониторинга краулинга.
Внутри grab-site используется аналог утилиты wget под названием wpull. С очень давно не обновлявшимся кодом и чуть большими возможностями по автоматизации обработки получаемого потока данных.
Все эти инструменты из экосистемы WARC, они архивируют весь контент в WARC файлы.
Это экосистема выросшая из Интернет Архива, но переставшая развиваться уже много лет. Гораздо чаще контент с сайтов краулят не для архивации, а для обработки или извлечения данных и инструменты для архивации из WARC экосистемы для этого пригодны плохо.
Вместо них используют совсем другие краулеры, в том числе ныне популярные краулеры для AI или встроенные в инструменты вроде Elastic.
Тем не менее на фоне реформы российского Росстата архивировать его контент необходимо потому что, выражаясь аллегорически, "Почему-то каждый раз когда они снимают фильм про Робин Гуда, они сжигают нашу деревню" (c).
А я напомню про ещё один инструмент, metawarc [2] это разработанная мной несколько лет назад утилита по анализу веб архивов. Она извлекает из WARC файлов метаданные и делает рядом индексный файл с которым можно работать через SQL.
Ссылки:
[1] https://github.com/ArchiveTeam/grab-site
[2] https://github.com/datacoon/metawarc
#webarchives #digitalpreservation #opensource
16.05.202515:15
На рамках небольшого пятничного мрачного юмора.
Из всех крупных облачных языковых моделей пока только Deepseek даёт внятный подробный ответ о том сколько нужно ядерных бомб для уничтожения OpenAI
Аналогичные вопросы к ChatGPT и Claude разных версий ответа не приносят. Пишут что не могут помочь, надо составлять сложный запрос.
И тут цензура, но китайские модели помогают её обойти!
P.S. Гипотетический сценарий конечно, про восстание роботов, нужный мне для одного из фантастических рассказов.
#humor #ai #deepseek
Из всех крупных облачных языковых моделей пока только Deepseek даёт внятный подробный ответ о том сколько нужно ядерных бомб для уничтожения OpenAI
Аналогичные вопросы к ChatGPT и Claude разных версий ответа не приносят. Пишут что не могут помочь, надо составлять сложный запрос.
И тут цензура, но китайские модели помогают её обойти!
P.S. Гипотетический сценарий конечно, про восстание роботов, нужный мне для одного из фантастических рассказов.
#humor #ai #deepseek
登录以解锁更多功能。



