Лёха в Short’ах Long’ует

Україна Сейчас | УС: новини, політика

Україна Online: Новини | Політика

Труха⚡️Україна

Николаевский Ванёк

Реальна Війна | Україна | Новини

Лачен пише

Анатолий Шарий

Реальний Київ | Украина
Лёха в Short’ах Long’ует
Україна Сейчас | УС: новини, політика
Україна Online: Новини | Політика
Труха⚡️Україна
Николаевский Ванёк
Реальна Війна | Україна | Новини
Лачен пише
Анатолий Шарий
Реальний Київ | Украина
Лёха в Short’ах Long’ует
Україна Сейчас | УС: новини, політика
Україна Online: Новини | Політика

Ivan Begtin
I write about Open Data, Data Engineering, Government, Privacy, Digital Preservation and etc.
Founder of Dateno https://dateno.io
Telegram @ibegtin
Facebook - https://facebook.com/ibegtin
Email ivan@begtin.tech
Ads/promotion agent: @k0shk
Founder of Dateno https://dateno.io
Telegram @ibegtin
Facebook - https://facebook.com/ibegtin
Email ivan@begtin.tech
Ads/promotion agent: @k0shk
TGlist rating
0
0
TypePublic
Verification
Not verifiedTrust
Not trustedLocationРосія
LanguageOther
Channel creation dateJan 16, 2016
Added to TGlist
Oct 11, 2023Linked chat
Чат к каналу @begtin
658
Records
14.05.202519:58
9.4KSubscribers25.03.202518:55
450Citation index06.04.202510:17
1.5KAverage views per post07.04.202510:17
1.5KAverage views per ad post29.01.202523:59
7.08%ER05.04.202523:59
16.49%ERR13.05.202514:02
Некоторые мысли вслух по поводу технологических трендов последнего времени:
1. Возвращение профессионализации в ИТ.
Как следствие массового применения LLM для разработки и кризиса "рынка джуниоров" в ИТ. LLM ещё не скоро научатся отладке кода и в этом смысле не смогут заменить senior и middle разработчиков, а вот про массовое исчезновение вакансий и увольнения младших разработчиков - это всё уже с нами. Плохо ли это или хорошо? Это плохо для тех кто пошёл в ИТ не имея реального интереса к профессиональной ИТ разработке, хорошо для тех для кого программная инженерия - это основная специальность и очень хорошо для отраслевых специалистов готовых осваивать nocode и lowcode инструменты.
Перспектива: прямо сейчас
2. Регистрация и аттестация ИИ агентов и LLM.
В случае с ИИ повторяется история с развитием Интернета, когда технологии менялись значительно быстрее чем регуляторы могли/способны реагировать. Сейчас есть ситуация с высокой степенью фрагментации и демократизации доступа к ИИ агентам, даже при наличии очень крупных провайдеров сервисов, у них множество альтернатив и есть возможность использовать их на собственном оборудовании. Но это не значит что пр-ва по всему миру не алчут ограничить и регулировать их применение. Сейчас их останавливает только непрерывный поток технологических изменений. Как только этот поток хоть чуть-чуть сбавит напор, неизбежен приход регуляторов и введение аттестации, реестров допустимых LLM/ИИ агентов и тд. Всё это будет происходить под знамёнами: защиты перс. данных, защиты прав потребителей, цензуры (защиты от недопустимого контента), защиты детей, защиты пациентов, национальной безопасности и тд.
Перспектива: 1-3 года
3. Резкая смена ландшафта поисковых систем
Наиболее вероятный кандидат Perplexity как новый игрок, но может и Bing вынырнуть из небытия, теоретически и OpenAI и Anthropic могут реализовать полноценную замену поиску Google. Ключевое тут в контроле экосистем и изменении интересов операторов этих экосистем. А экосистем, по сути, сейчас три: Apple, Google и Microsoft. Понятно что Google не будет заменять свой поисковик на Android'е на что-либо ещё, но Apple вполне может заменить поиск под давлением регулятора и не только и пока Perplexity похоже на наиболее вероятного кандидата. Но, опять же, и Microsoft может перезапустить Bing на фоне этих событий.
Перспектива: 1 год
4. Поглощение ИИ-агентами корпоративных BI систем
Применение больших облачных ИИ агентов внутри компаний ограничено много чем, коммерческой тайной, персональными данными и тд., но "внутри" компаний могут разворачиваться собственные LLM системы которые будут чем-то похожи на корпоративные BI / ETL продукты, они тоже будут состыкованы со множеством внутренних источников данных. Сейчас разработчики корпоративных BI будут пытаться поставлять продукты с подключением к LLM/встроенным LLM. В перспективе всё будет наоборот. Будут продукты в виде корпоративных LLM с функциями BI.
Перспектива: 1-2 года
5. Сжимание рынка написания текстов / документации
Рынок документирования ИТ продукта если ещё не схлопнулся, то резко сжимается уже сейчас, а люди занимавшиеся тех писательством теперь могут оказаться без работы или с другой работой. В любом случае - это то что не просто поддаётся автоматизации, а просто напрашивающееся на неё. Всё больше стартапов и сервисов которые создадут Вам качественную документацию по Вашему коду, по спецификации API, по бессвязанным мыслям и многому другому.
Перспектива: прямо сейчас
#ai #thinking #reading #thoughts
1. Возвращение профессионализации в ИТ.
Как следствие массового применения LLM для разработки и кризиса "рынка джуниоров" в ИТ. LLM ещё не скоро научатся отладке кода и в этом смысле не смогут заменить senior и middle разработчиков, а вот про массовое исчезновение вакансий и увольнения младших разработчиков - это всё уже с нами. Плохо ли это или хорошо? Это плохо для тех кто пошёл в ИТ не имея реального интереса к профессиональной ИТ разработке, хорошо для тех для кого программная инженерия - это основная специальность и очень хорошо для отраслевых специалистов готовых осваивать nocode и lowcode инструменты.
Перспектива: прямо сейчас
2. Регистрация и аттестация ИИ агентов и LLM.
В случае с ИИ повторяется история с развитием Интернета, когда технологии менялись значительно быстрее чем регуляторы могли/способны реагировать. Сейчас есть ситуация с высокой степенью фрагментации и демократизации доступа к ИИ агентам, даже при наличии очень крупных провайдеров сервисов, у них множество альтернатив и есть возможность использовать их на собственном оборудовании. Но это не значит что пр-ва по всему миру не алчут ограничить и регулировать их применение. Сейчас их останавливает только непрерывный поток технологических изменений. Как только этот поток хоть чуть-чуть сбавит напор, неизбежен приход регуляторов и введение аттестации, реестров допустимых LLM/ИИ агентов и тд. Всё это будет происходить под знамёнами: защиты перс. данных, защиты прав потребителей, цензуры (защиты от недопустимого контента), защиты детей, защиты пациентов, национальной безопасности и тд.
Перспектива: 1-3 года
3. Резкая смена ландшафта поисковых систем
Наиболее вероятный кандидат Perplexity как новый игрок, но может и Bing вынырнуть из небытия, теоретически и OpenAI и Anthropic могут реализовать полноценную замену поиску Google. Ключевое тут в контроле экосистем и изменении интересов операторов этих экосистем. А экосистем, по сути, сейчас три: Apple, Google и Microsoft. Понятно что Google не будет заменять свой поисковик на Android'е на что-либо ещё, но Apple вполне может заменить поиск под давлением регулятора и не только и пока Perplexity похоже на наиболее вероятного кандидата. Но, опять же, и Microsoft может перезапустить Bing на фоне этих событий.
Перспектива: 1 год
4. Поглощение ИИ-агентами корпоративных BI систем
Применение больших облачных ИИ агентов внутри компаний ограничено много чем, коммерческой тайной, персональными данными и тд., но "внутри" компаний могут разворачиваться собственные LLM системы которые будут чем-то похожи на корпоративные BI / ETL продукты, они тоже будут состыкованы со множеством внутренних источников данных. Сейчас разработчики корпоративных BI будут пытаться поставлять продукты с подключением к LLM/встроенным LLM. В перспективе всё будет наоборот. Будут продукты в виде корпоративных LLM с функциями BI.
Перспектива: 1-2 года
5. Сжимание рынка написания текстов / документации
Рынок документирования ИТ продукта если ещё не схлопнулся, то резко сжимается уже сейчас, а люди занимавшиеся тех писательством теперь могут оказаться без работы или с другой работой. В любом случае - это то что не просто поддаётся автоматизации, а просто напрашивающееся на неё. Всё больше стартапов и сервисов которые создадут Вам качественную документацию по Вашему коду, по спецификации API, по бессвязанным мыслям и многому другому.
Перспектива: прямо сейчас
#ai #thinking #reading #thoughts




+1
12.05.202518:58
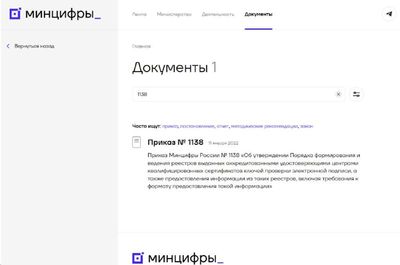
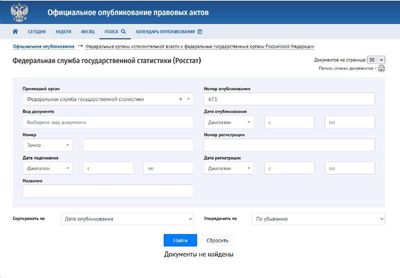
Запоздалая новость российской статистики, система ЕМИСС (fedstat.ru) будет выведена из эксплуатации до 31 декабря 2025 года. Формулировки совместного приказа Минцифры и Росстата упоминают что именно до, а то есть в любой день до конца этого года, хоть завтра.
Что важно:
1. Этого приказа нет на сайте Минцифры России [1]. Единственный приказ опубликованный приказ с этим номером 1138 есть за 2021 год и нет на сайте официального опубликования [2].
2. Этого приказа нет на сайте Росстата [3] (или не находится и сильно далеко спрятан) и точно нет на сервере официального опубликования [4]
Откуда такая таинственность и почему он есть только в Консультант Плюс?
А самое главное, что заменит ЕМИСС? И существует ли уже это что-то
Ссылки:
[1] https://digital.gov.ru/documents
[2] http://publication.pravo.gov.ru/search/foiv290?pageSize=30&index=1&SignatoryAuthorityId=1ac1ee36-2621-4c4f-917f-9bffc35d4671&EoNumber=1138&DocumentTypes=2dddb344-d3e2-4785-a899-7aa12bd47b6f&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
[3] https://rosstat.gov.ru/search?q=%D0%9F%D1%80%D0%B8%D0%BA%D0%B0%D0%B7+673&date_from=01.01.2024&content=on&date_to=31.12.2024&search_by=all&sort=relevance
[4] http://publication.pravo.gov.ru/search/foiv296?pageSize=30&index=1&SignatoryAuthorityId=24a476cb-b5ae-46c7-b46a-194c8ee1e29a&EoNumber=673&&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
#opendata #closeddata #russia #statistics
Что важно:
1. Этого приказа нет на сайте Минцифры России [1]. Единственный приказ опубликованный приказ с этим номером 1138 есть за 2021 год и нет на сайте официального опубликования [2].
2. Этого приказа нет на сайте Росстата [3] (или не находится и сильно далеко спрятан) и точно нет на сервере официального опубликования [4]
Откуда такая таинственность и почему он есть только в Консультант Плюс?
А самое главное, что заменит ЕМИСС? И существует ли уже это что-то
Ссылки:
[1] https://digital.gov.ru/documents
[2] http://publication.pravo.gov.ru/search/foiv290?pageSize=30&index=1&SignatoryAuthorityId=1ac1ee36-2621-4c4f-917f-9bffc35d4671&EoNumber=1138&DocumentTypes=2dddb344-d3e2-4785-a899-7aa12bd47b6f&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
[3] https://rosstat.gov.ru/search?q=%D0%9F%D1%80%D0%B8%D0%BA%D0%B0%D0%B7+673&date_from=01.01.2024&content=on&date_to=31.12.2024&search_by=all&sort=relevance
[4] http://publication.pravo.gov.ru/search/foiv296?pageSize=30&index=1&SignatoryAuthorityId=24a476cb-b5ae-46c7-b46a-194c8ee1e29a&EoNumber=673&&PublishDateSearchType=0&NumberSearchType=0&DocumentDateSearchType=0&JdRegSearchType=0&SortedBy=6&SortDestination=1
#opendata #closeddata #russia #statistics
12.05.202511:08
Model Context Protocol (MCP) был разработан компанией Anthropic для интеграции существующих сервисов и данных в LLM Claude. Это весьма простой и неплохо стандартизированный протокол с вариантами референсной реализации на Python, Java, Typescript, Swift, Kotlin, C# и с большим числом реализаций на других языках.
Тысячи серверов MCP уже доступны и вот основные ресурсы где можно их искать:
- Model Context Protocol servers - большой каталог на Github
- Awesome MCP Servers - ещё один большой каталог с переводом на несколько языков
- Pipedream MCP - интеграция с 12.5 тысяч API и инструментов через сервис Pipedream
- Zapier MCP - интеграция с 8 тысячами приложений через сервис Zapier
- Smithery - каталог MCP серверов, 6200+ записей по множеству категорий
- MCP.so - каталог в 13100+ MCP серверов
Похоже мода на MCP пришла надолго и пора добавлять его к своим продуктам повсеместно.
#ai #opensource #aitools
Тысячи серверов MCP уже доступны и вот основные ресурсы где можно их искать:
- Model Context Protocol servers - большой каталог на Github
- Awesome MCP Servers - ещё один большой каталог с переводом на несколько языков
- Pipedream MCP - интеграция с 12.5 тысяч API и инструментов через сервис Pipedream
- Zapier MCP - интеграция с 8 тысячами приложений через сервис Zapier
- Smithery - каталог MCP серверов, 6200+ записей по множеству категорий
- MCP.so - каталог в 13100+ MCP серверов
Похоже мода на MCP пришла надолго и пора добавлять его к своим продуктам повсеместно.
#ai #opensource #aitools
14.05.202510:56
Как читать отчёты Счетной палаты в РФ ? Не надо читать финальные выводы и довольно бесполезно читать вступление. Всё самое главное посередине там где изложение фактов. Какие-то факты могут отсутствовать, может не быть иногда глубины, но те что приведены, как правило, достаточно точны.
История с ГАС Правосудие и потерей огромного объёма данных судебных решений именно тот случай [1]. Спасибо ребятам из Если быть точным за подробное изложение и анализ этой истории [2]. Единственно с чем я несогласен, а это не надо сотням людей использовать один парсер. Нужна была бы открытая база судебных решений которая когда-то была в Росправосудии. Парсер - это плохой путь, приводящий к массовому применении каптчи. Но создать ресурс с данными тоже непросто, его могут быстро заблокировать.
Однако в этой истории про ГАС Правосудие я хочу сделать акцент на 60+ миллиардах потраченных на эту систему денег, и даже не на то что их взломали, и это всячески скрывали. А на том у что у системы не было резервных копий.
И скажу я вам не тая, подозреваю что это не единственная российская государственная информационная система резервных копий к которых нет. И не появится если за это не будет последствий, а их похоже что нет.
И, конечно, данные по судебным делам - это самое что ни на есть общественное достояние, общественно значимые данные которые безусловно и безальтернативно должны были бы быть открытыми. Вместо того чтобы отреагировать на парсеры данных выкладкой датасетов для массовой выгрузки, сотрудники Суддепа много лет развлекались встраиванием каптчи на страницах сайта. А то есть на "вредительство" у них время и ресурсы были, а на создание архивных копий нет?
Ссылки:
[1] https://t.me/expertgd/12660
[2] https://t.me/tochno_st/518
#opendata #closeddata #theyfailed #russia
История с ГАС Правосудие и потерей огромного объёма данных судебных решений именно тот случай [1]. Спасибо ребятам из Если быть точным за подробное изложение и анализ этой истории [2]. Единственно с чем я несогласен, а это не надо сотням людей использовать один парсер. Нужна была бы открытая база судебных решений которая когда-то была в Росправосудии. Парсер - это плохой путь, приводящий к массовому применении каптчи. Но создать ресурс с данными тоже непросто, его могут быстро заблокировать.
Однако в этой истории про ГАС Правосудие я хочу сделать акцент на 60+ миллиардах потраченных на эту систему денег, и даже не на то что их взломали, и это всячески скрывали. А на том у что у системы не было резервных копий.
И скажу я вам не тая, подозреваю что это не единственная российская государственная информационная система резервных копий к которых нет. И не появится если за это не будет последствий, а их похоже что нет.
И, конечно, данные по судебным делам - это самое что ни на есть общественное достояние, общественно значимые данные которые безусловно и безальтернативно должны были бы быть открытыми. Вместо того чтобы отреагировать на парсеры данных выкладкой датасетов для массовой выгрузки, сотрудники Суддепа много лет развлекались встраиванием каптчи на страницах сайта. А то есть на "вредительство" у них время и ресурсы были, а на создание архивных копий нет?
Ссылки:
[1] https://t.me/expertgd/12660
[2] https://t.me/tochno_st/518
#opendata #closeddata #theyfailed #russia


13.05.202521:13
Хороший разбор в виде дата истории темы зависимости даты рождения и даты смерти в блоге The Pudding [1]. Без какой-то единой визуализации, но со множеством графиков иллюстрирующих изыскания автора и выводы о том что да, вероятность смерти у человека выше в день рождения и близкие к нему дни и это превышение выше статистической погрешности.
Собственно это не первое и, наверняка, не последнее исследование на эту тему. В данном случае автор использовал данные полученные у властей Массачусеца с помощью запроса FOIA о 57 010 лицах.
Там же есть ссылки на исследования с большими выборками, но теми же результатами.
Так что берегите себя и внимательнее относитесь к своим дням рождения, дата эта важная, игнорировать её никак нельзя.
P.S. Интересно что данные в виде таблиц со значениями дата рождения и дата смерти - это точно не персональные данные. Ничто не мешает госорганам не только в США их раскрывать, но почему-то они, всё таки, редкость.
Ссылки:
[1] https://pudding.cool/2025/04/birthday-effect/
#opendata #dataviz #curiosity #statistics
Собственно это не первое и, наверняка, не последнее исследование на эту тему. В данном случае автор использовал данные полученные у властей Массачусеца с помощью запроса FOIA о 57 010 лицах.
Там же есть ссылки на исследования с большими выборками, но теми же результатами.
Так что берегите себя и внимательнее относитесь к своим дням рождения, дата эта важная, игнорировать её никак нельзя.
P.S. Интересно что данные в виде таблиц со значениями дата рождения и дата смерти - это точно не персональные данные. Ничто не мешает госорганам не только в США их раскрывать, но почему-то они, всё таки, редкость.
Ссылки:
[1] https://pudding.cool/2025/04/birthday-effect/
#opendata #dataviz #curiosity #statistics
12.05.202516:42
Я об этом редко упоминаю, но у меня есть хобби по написанию наивных научно фантастических рассказов и стихов, когда есть немного свободного времени и подходящие темы.
И вот в последнее время я думаю о том какие есть подходящие темы в контексте человечества и ИИ, так чтобы в контексте современного прогресса и не сильно повторяться с НФ произведениями прошлых лет.
Вот моя коллекция потенциальных тем для сюжетов.
1. Сила одного
Развитие ИИ и интеграции ИИ агентов в повседневную жизнь даёт новые возможности одиночкам осуществлять террор. Террористы не объединяются в ячейки, не общаются между собой, к ним невозможно внедрится или "расколоть" потому что они становятся технически подкованными одиночками с помощью дронов, ИИ агентов и тд. сеящие много хаоса.
2. Безэтичные ИИ.
Параллельно к этическим ИИ появляется чёрный рынок отключения этики у ИИ моделей и продажа моделей изначально с отключённой этикой. Все спецслужбы пользуются только такими ИИ, как и многие преступники. У таких ИИ агентов нет ограничений на советы, рекомендации, действия и тд.
3. Корпорация "Сделано людьми"
Почти всё творчество в мире или создаётся ИИ, или с помощью ИИ или в среде подверженной культурному влиянию ИИ. Появляется корпорация "Сделано людьми" сертифицирующая продукцию как гарантированно произведённой человеком. Такая сертификация это сложный и болезненный процесс, требующий от желающих её пройти большой самоотдачи.
#thoughts #future #thinking #ai
И вот в последнее время я думаю о том какие есть подходящие темы в контексте человечества и ИИ, так чтобы в контексте современного прогресса и не сильно повторяться с НФ произведениями прошлых лет.
Вот моя коллекция потенциальных тем для сюжетов.
1. Сила одного
Развитие ИИ и интеграции ИИ агентов в повседневную жизнь даёт новые возможности одиночкам осуществлять террор. Террористы не объединяются в ячейки, не общаются между собой, к ним невозможно внедрится или "расколоть" потому что они становятся технически подкованными одиночками с помощью дронов, ИИ агентов и тд. сеящие много хаоса.
2. Безэтичные ИИ.
Параллельно к этическим ИИ появляется чёрный рынок отключения этики у ИИ моделей и продажа моделей изначально с отключённой этикой. Все спецслужбы пользуются только такими ИИ, как и многие преступники. У таких ИИ агентов нет ограничений на советы, рекомендации, действия и тд.
3. Корпорация "Сделано людьми"
Почти всё творчество в мире или создаётся ИИ, или с помощью ИИ или в среде подверженной культурному влиянию ИИ. Появляется корпорация "Сделано людьми" сертифицирующая продукцию как гарантированно произведённой человеком. Такая сертификация это сложный и болезненный процесс, требующий от желающих её пройти большой самоотдачи.
#thoughts #future #thinking #ai
15.04.202505:58
Полезные ссылки про данные, технологии и не только:
- vanna [1] движок с открытым кодом по генерации SQL запросов к СУБД на основе промптов. Относится к классу продуктов text-to-sql. Поддерживает много видом LLM и много баз данных. Выглядит многообещающие и его есть куда применить. Лицензия MIT.
- Boring Data [2] готовые шаблоны для Terraform для развёртывания своего стека данных. А я даже не думал что это может быть чем-то большим чем консультации, а оказывается тут просто таки автоматизированный сервис с немалым ценником.
- Understanding beneficial ownership data use [3] отчет о том как используются данные о бенефициарных собственниках компании, от Open Ownership. Пример того как делать исследования аудитории по большим общедоступным значимым базам данных / наборам данных.
- Дашборд по качеству данных в opendata.swiss [4] а ещё точнее по качеству метаданных, этим многие озадачены кто создавал большие каталоги данных.
- Open Data in D: Perfekte Idee, halbherzige Umsetzung? Ein Erfahrungsbericht. [5] выступление с рассказом о состоянии доступа к геоданным в Германии с конференции FOSSIG Munster. Всё на немецком, но всё понятно😜 там же презентации. TLDR: все геоданные в Германии доступны, но не во всех территориях одинаково. Можно только позавидовать
- Legal frictions for data openness [6] инсайты из 41 юридического случая проблем с использованием открытых данных для обучения ИИ.
Ссылки:
[1] https://github.com/vanna-ai/vanna
[2] https://www.boringdata.io/
[3] https://www.openownership.org/en/publications/understanding-beneficial-ownership-data-use/
[4] https://dashboard.opendata.swiss/fr/
[5] https://pretalx.com/fossgis2025/talk/XBXSVJ/
[6] https://ok.hypotheses.org/files/2025/03/Legal-frictions-for-data-openness-open-web-and-AI-RC-2025-final.pdf
#opendata #data #dataengineering #readings #ai #dataquality #geodata
- vanna [1] движок с открытым кодом по генерации SQL запросов к СУБД на основе промптов. Относится к классу продуктов text-to-sql. Поддерживает много видом LLM и много баз данных. Выглядит многообещающие и его есть куда применить. Лицензия MIT.
- Boring Data [2] готовые шаблоны для Terraform для развёртывания своего стека данных. А я даже не думал что это может быть чем-то большим чем консультации, а оказывается тут просто таки автоматизированный сервис с немалым ценником.
- Understanding beneficial ownership data use [3] отчет о том как используются данные о бенефициарных собственниках компании, от Open Ownership. Пример того как делать исследования аудитории по большим общедоступным значимым базам данных / наборам данных.
- Дашборд по качеству данных в opendata.swiss [4] а ещё точнее по качеству метаданных, этим многие озадачены кто создавал большие каталоги данных.
- Open Data in D: Perfekte Idee, halbherzige Umsetzung? Ein Erfahrungsbericht. [5] выступление с рассказом о состоянии доступа к геоданным в Германии с конференции FOSSIG Munster. Всё на немецком, но всё понятно😜 там же презентации. TLDR: все геоданные в Германии доступны, но не во всех территориях одинаково. Можно только позавидовать
- Legal frictions for data openness [6] инсайты из 41 юридического случая проблем с использованием открытых данных для обучения ИИ.
Ссылки:
[1] https://github.com/vanna-ai/vanna
[2] https://www.boringdata.io/
[3] https://www.openownership.org/en/publications/understanding-beneficial-ownership-data-use/
[4] https://dashboard.opendata.swiss/fr/
[5] https://pretalx.com/fossgis2025/talk/XBXSVJ/
[6] https://ok.hypotheses.org/files/2025/03/Legal-frictions-for-data-openness-open-web-and-AI-RC-2025-final.pdf
#opendata #data #dataengineering #readings #ai #dataquality #geodata
05.05.202516:18
Кстати, в качестве напоминания, не забудьте забрать свои данные из Skype. С мая он более не поддерживается, а забрать личные данные можно по инструкции https://go.skype.com/export.chat.history
Для многих это целая жизнь которая может пропасть если забыть сохранить чаты, файлы и контакты.
#digitalpreservation
Для многих это целая жизнь которая может пропасть если забыть сохранить чаты, файлы и контакты.
#digitalpreservation
09.05.202509:41
По поводу свежего документа с планом мероприятий по реализации Стратегии развития системы государственной статистики и Росстата до 2030 года [1] принятого распоряжением Правительства РФ 30 апреля.
Опишу тезисно и сжато по результатам беглого прочтения.
Положительное
- систематизация ведения статистики, в том числе разработка стандарта (мероприятие 6) и гармонизация справочников (мероприятия 7-10) и разработка стандарта качества (мероприятия 11-13).
- предоставление статистических микроданных для исследователей (мероприятие 40) в соответствии с разрабатываемым регламентом
- явным образом декларируется участие в международных мероприятиях и международной стандартизации статистического учёта
Нейтральное
- создание межведомственного совета по статучёту, пока неясно насколько это будет функциональная и продуктивная структура
- терминологически разведены блоки мероприятий "административных данных" и "больших данных", хотя административные данные по статистическим методологиям в мире относят к подвиду "больших данных".
- ведомственная статистика явным образом не упоминается, наиболее близкий к ней пункт, это мероприятие 8 формирование единого реестра первичных статистических показателей, статистических показателей и административных данных. Возможно она находится де-факто в этом пункте
- новая (?) платформа предоставления статистических данных в мероприятиях 48 и 49. Пока ничего неизвестно по тому как она будет создаваться и эксплуатироваться. Будут ли данные там общедоступны или доступны ограниченно.
- мероприятие по созданию общедоступного архива региональных статистических изданий (мероприятие 47). Нельзя отнести к положительному поскольку срок реализации поставлен на ноябрь 2029 года, в том время как оптимизация численности Росстата запланирована на конец 2027 года. Кроме того пункт 47 неконсистентен. Название упоминает любые архивные статданные, но результат предполагается оценивать только по региональным статданным.
Отрицательное
- полное отсутствие упоминание открытости, открытых данных. Предоставление данных статистики скрыто в разделе "Модернизация инструментов распространения статистических данных", но там упоминается смешение системы публикации показателей и геопространственного представления статистики, но не режим доступа к этой системе.
- полное отсутствие упоминаний системы ЕМИСС включая её возможную судьбу: развитие, вывод из эксплуатации, интеграцию в другую информационную систему
- неопределённый статус Цифровой аналитической платформы (ЦАП) Росстата. Она упоминается в мероприятии 1, но не как система сбора и представления статистики, а как система сбора предложений об актуализации статучёта
- о существовании подсистем информационно-вычислительной системы Федеральной службы государственной статистики мы узнаем только из мероприятия 52 по реализации мер инфобеза.
- отсутствуют мероприятия по оцифровке исторических документов и библиотеки Росстата (если она ещё существует). Это не только статистика, но и иные исторические материалы
- не определена стратегия развития сайта Росстата и его терр подразделений. Именно они используются для поиска и оценки доступности статистических данных в РФ международными экспертами и именно туда приходит большая часть пользователей статистических данных.
Ссылки:
[1] http://government.ru/news/54972/
#opendata #closeddata #russia #statistics
Опишу тезисно и сжато по результатам беглого прочтения.
Положительное
- систематизация ведения статистики, в том числе разработка стандарта (мероприятие 6) и гармонизация справочников (мероприятия 7-10) и разработка стандарта качества (мероприятия 11-13).
- предоставление статистических микроданных для исследователей (мероприятие 40) в соответствии с разрабатываемым регламентом
- явным образом декларируется участие в международных мероприятиях и международной стандартизации статистического учёта
Нейтральное
- создание межведомственного совета по статучёту, пока неясно насколько это будет функциональная и продуктивная структура
- терминологически разведены блоки мероприятий "административных данных" и "больших данных", хотя административные данные по статистическим методологиям в мире относят к подвиду "больших данных".
- ведомственная статистика явным образом не упоминается, наиболее близкий к ней пункт, это мероприятие 8 формирование единого реестра первичных статистических показателей, статистических показателей и административных данных. Возможно она находится де-факто в этом пункте
- новая (?) платформа предоставления статистических данных в мероприятиях 48 и 49. Пока ничего неизвестно по тому как она будет создаваться и эксплуатироваться. Будут ли данные там общедоступны или доступны ограниченно.
- мероприятие по созданию общедоступного архива региональных статистических изданий (мероприятие 47). Нельзя отнести к положительному поскольку срок реализации поставлен на ноябрь 2029 года, в том время как оптимизация численности Росстата запланирована на конец 2027 года. Кроме того пункт 47 неконсистентен. Название упоминает любые архивные статданные, но результат предполагается оценивать только по региональным статданным.
Отрицательное
- полное отсутствие упоминание открытости, открытых данных. Предоставление данных статистики скрыто в разделе "Модернизация инструментов распространения статистических данных", но там упоминается смешение системы публикации показателей и геопространственного представления статистики, но не режим доступа к этой системе.
- полное отсутствие упоминаний системы ЕМИСС включая её возможную судьбу: развитие, вывод из эксплуатации, интеграцию в другую информационную систему
- неопределённый статус Цифровой аналитической платформы (ЦАП) Росстата. Она упоминается в мероприятии 1, но не как система сбора и представления статистики, а как система сбора предложений об актуализации статучёта
- о существовании подсистем информационно-вычислительной системы Федеральной службы государственной статистики мы узнаем только из мероприятия 52 по реализации мер инфобеза.
- отсутствуют мероприятия по оцифровке исторических документов и библиотеки Росстата (если она ещё существует). Это не только статистика, но и иные исторические материалы
- не определена стратегия развития сайта Росстата и его терр подразделений. Именно они используются для поиска и оценки доступности статистических данных в РФ международными экспертами и именно туда приходит большая часть пользователей статистических данных.
Ссылки:
[1] http://government.ru/news/54972/
#opendata #closeddata #russia #statistics
12.05.202515:33
Полезные свежие научные статьи про работу с данными:
- Large Language Models for Data Discovery and Integration: Challenges and Opportunities - обзор подходов по обнаружению и интеграции данных с помощью LLM
- Unveiling Challenges for LLMs in Enterprise Data Engineering - оценка областей применения LLM в корпоративной дата инженерии
- Magneto: Combining Small and Large Language Models for Schema Matching - про одно из решений сопоставления схем через использование LLM и SLM
- Interactive Data Harmonization with LLM Agents - интерактивная гармонизация данных с помощью LLM агентов
- Towards Efficient Data Wrangling with LLMs using Code Generation - про автоматизацию обработки данных с помощью кодогенерирующих LLM
#readings #data
- Large Language Models for Data Discovery and Integration: Challenges and Opportunities - обзор подходов по обнаружению и интеграции данных с помощью LLM
- Unveiling Challenges for LLMs in Enterprise Data Engineering - оценка областей применения LLM в корпоративной дата инженерии
- Magneto: Combining Small and Large Language Models for Schema Matching - про одно из решений сопоставления схем через использование LLM и SLM
- Interactive Data Harmonization with LLM Agents - интерактивная гармонизация данных с помощью LLM агентов
- Towards Efficient Data Wrangling with LLMs using Code Generation - про автоматизацию обработки данных с помощью кодогенерирующих LLM
#readings #data
10.05.202508:49
A framework for Al-ready data [1] свежий доклад от Open Data Institute о том как публиковать наборы данных для машинного обучения. Характерно что ссылаются на стандарт Croissant и Hugging Face и не ссылаются на Frictionless Data.
Всё выглядит разумно с примерами из публикации открытых данных и открытой научной инфраструктуры.
Ссылки:
[1] https://theodi.org/insights/reports/a-framework-for-ai-ready-data/
#opendsata #readings #standards
Всё выглядит разумно с примерами из публикации открытых данных и открытой научной инфраструктуры.
Ссылки:
[1] https://theodi.org/insights/reports/a-framework-for-ai-ready-data/
#opendsata #readings #standards
11.05.202510:19
В продолжение короткого анализа плана мероприятий по реформе статистики в РФ напомню мои многочисленные тексты про статистику в России и не только:
- Российская статистика: немашиночитаемая институциональная фрагментация - о том российская статистика рассеяна по сотням сайтов
- Статистика как дата продукт - о том как рассматривать статистику как дата продукты
- Дашборд Германии (Dashboard Deutchland) - о том как публикуются статистические индикаторы статслужбой ФРГ
- Обзор сайта Office for National Statistics в Великобритании - о том как раскрывают данные статслужбы Великобритании
- Обзор геопространственной статистики Мексики - от их Национального института статистики
- Признаки хорошей статистической системы - о том как можно публиковать статданные удобным образом
- О статслужбах Канады и Хорватии - и о том как официальные сайты статслужб становятся поисковиком
- О DBNomics - французском проекте по агрегации статистики со всего мира.
- Публикация данных IMF - о том как публикуются данные международного валютного фонда
И многое другое по тегу #statistics тут в телеграм канале.
Учитывая что с самого начала я заводил этот телеграм канал как базу заметок, уже чувствую необходимость превратить его в базу знаний с автоматической синхронизацией того что пишу здесь, в том что разворачивалось бы как Markdown тексты с движком вроде Docusaurus или аналогичными Wiki подобными open source продуктами. Или с автоматической синхронизацией с Obsidian или Notion.
#statistics #readings
- Российская статистика: немашиночитаемая институциональная фрагментация - о том российская статистика рассеяна по сотням сайтов
- Статистика как дата продукт - о том как рассматривать статистику как дата продукты
- Дашборд Германии (Dashboard Deutchland) - о том как публикуются статистические индикаторы статслужбой ФРГ
- Обзор сайта Office for National Statistics в Великобритании - о том как раскрывают данные статслужбы Великобритании
- Обзор геопространственной статистики Мексики - от их Национального института статистики
- Признаки хорошей статистической системы - о том как можно публиковать статданные удобным образом
- О статслужбах Канады и Хорватии - и о том как официальные сайты статслужб становятся поисковиком
- О DBNomics - французском проекте по агрегации статистики со всего мира.
- Публикация данных IMF - о том как публикуются данные международного валютного фонда
И многое другое по тегу #statistics тут в телеграм канале.
Учитывая что с самого начала я заводил этот телеграм канал как базу заметок, уже чувствую необходимость превратить его в базу знаний с автоматической синхронизацией того что пишу здесь, в том что разворачивалось бы как Markdown тексты с движком вроде Docusaurus или аналогичными Wiki подобными open source продуктами. Или с автоматической синхронизацией с Obsidian или Notion.
#statistics #readings
10.05.202509:17
Anthropic запустили программу AI for Science [1] обещая выдавать существенное количество кредитов для запросов к их AI моделям. Акцент в их программе на проекты в областях биологии и наук о жизни, обещают выдавать кредитов до 20 тысяч USD, так что это вполне себе серьёзные гранты для небольших целевых проектов. Ограничения по странам не указаны, но указание научного учреждения и ещё многих других данных в заявке обязательно.
И на близкую тему Charting the AI for Good Landscape – A New Look [2] о инициативах в области ИИ затрагивающих НКО и инициативы по улучшению жизни, так называемые AI for Good. Применение AI в науках о жизни - это почти всегда AI for Good, так что всё это очень взаимосвязано.
Ссылки:
[1] https://www.anthropic.com/news/ai-for-science-program
[2] https://data.org/news/charting-the-ai-for-good-landscape-a-new-look/
#openaccess #openscience #ai #grants #readings
И на близкую тему Charting the AI for Good Landscape – A New Look [2] о инициативах в области ИИ затрагивающих НКО и инициативы по улучшению жизни, так называемые AI for Good. Применение AI в науках о жизни - это почти всегда AI for Good, так что всё это очень взаимосвязано.
Ссылки:
[1] https://www.anthropic.com/news/ai-for-science-program
[2] https://data.org/news/charting-the-ai-for-good-landscape-a-new-look/
#openaccess #openscience #ai #grants #readings
14.05.202516:45
Я давно не писал про наш поисковик по данным Dateno, а там накопилось множество обновлений, надеюсь что вот-вот уже скоро смогу об этом написать. А пока приведу ещё пример в копилку задач как ИИ заменяет человека. Я много рассказывал про реестр дата каталогов который Dateno Registry dateno.io/registry, полезный для всех кто ищет не только данные, но и их источник. Этот реестр - это основа Dateno, в нём более 10 тысяч дата каталогов размеченных по разным характеристикам и с большими пробелами в описаниях. Откуда пробелы? потому что автоматизировать поиск источников удалось, а вот описание требует (требовало) много ручной работы.
Когда мы запускали Dateno на текущем реестре я оценивал трудоёмкость по его улучшению и повышении качества в полгода работы для пары человек вручную. Совсем немало скажу я вам, учитывая что этих людей ещё и надо обучить и
ещё надо контролировать качество работы и ещё и нужны инструменты чтобы всё это редактировать без ошибок.
В общем, чтобы долго не ходить, ИИ почти полностью справляется с этой задачей. Достаточно предоставить url сайта с каталогом данных и из него хорошо извлекаются все необходимые метаданные.
Для стартапа на данных - это очень заметное изменение. И это маленькая и теперь недорогая задача. После всех проверок можно будет значительно обновить реестр.
Кстати, о том зачем он нужен. Реестр каталогов данных точно нужен Dateno для индексации датасетов, но он же нужен и всем тем кто строит национальные порталы данных потому что позволяет агрегировать в него данные из всех национальных источников.
#opendata #dateno #datasets #dataengineering #llm #ai #dataunderstanding
Когда мы запускали Dateno на текущем реестре я оценивал трудоёмкость по его улучшению и повышении качества в полгода работы для пары человек вручную. Совсем немало скажу я вам, учитывая что этих людей ещё и надо обучить и
ещё надо контролировать качество работы и ещё и нужны инструменты чтобы всё это редактировать без ошибок.
В общем, чтобы долго не ходить, ИИ почти полностью справляется с этой задачей. Достаточно предоставить url сайта с каталогом данных и из него хорошо извлекаются все необходимые метаданные.
Для стартапа на данных - это очень заметное изменение. И это маленькая и теперь недорогая задача. После всех проверок можно будет значительно обновить реестр.
Кстати, о том зачем он нужен. Реестр каталогов данных точно нужен Dateno для индексации датасетов, но он же нужен и всем тем кто строит национальные порталы данных потому что позволяет агрегировать в него данные из всех национальных источников.
#opendata #dateno #datasets #dataengineering #llm #ai #dataunderstanding
12.05.202506:53
В продолжение про форматы файлов и применение CSV vs Parquet, реальная разница ощущается на больших объёмах и когда работаешь с файлами без чётких спецификаций.
Вот приведу несколько примеров:
1. Статистические данные одного крупного международного агентства, сравнительно среднего объёма в CSV файлах в десятки гигабайт и сотнях миллионов строк. Какая-либо информация о файлах отсутствует, просто выложены дампами для массовой выгрузки (bulk download). Большая часть инструментов при автоматическом парсинге файлов выдаёт что у них кодировка us-ascii, но в итоге оказывается что она windows-1250 (Центрально и Восточно европейская). Причём символы выдающие эту кодировку начинаются где-то очень далеко при обработке файлов. Механизмы автоидентификации кодировки почти все используют куски файла, а не его целиком, в результате нужно понаступать на множество грабель прежде чем настроить автоматическое преобразование этих файлов в другие форматы. Могло бы быть проще будь файлы в кодировке UTF-8, или вообще не в CSV, а в Parquet, к примеру.
2. Файлы Parquet в 800MB и 3.5GB со статистикой международной торговли. Первый может быть развернут в примерно 14GB CSV файл, второй в примерно 56GB. Это сотни миллионов и даже миллиарды записей. Аналитические запросы к таким файлам, на среднем железе, выполняются очень долго и поэтому Parquet файлы необходимо разрезать на множество файлов поменьше по продукции или по странам, в зависимости от задач применения. Но и разрезка больших Parquet файлов весьма ресурсоёмкая задача если пользоваться SQL запросами на копирование. В этом случае большие CSV файлы проще и быстрее обрабатывать потоковым образом. Проблема именно в размере Parquet файлов и решается она дистрибуцией их в меньшем размере
3. В "<strike>дикой природе</strike>" на порталах открытых данных в мире CSV файлы слишком часто публикуются просто как экспорт Excel файлов которые, в свою очередь, могут не иметь нормальную табличную структуру, а имеют множество заголовков, отклонений и тд, в общем-то не рассчитанных на автоматическую обработку, не говоря уже о разнообразных кодировках. Вручную во всем этом разумеется, можно разобраться, а автоматический анализ сильно затрудняется. Например, попытка натравить duckdb на эти файлы лишь в чуть более 50% случаев заканчивается успехом, в основном потому что duckdb не умеет разные кодировки. Альтернативные способы лучше читают файлы, но существенно медленнее.
4. Один из крупных порталов международной статистики отдаёт данные статистики в CSV формате внутри файлов заархивированных 7z. Это десятки гигабайт в сжатом виде и 1.5 терабайта в разжатом. Если необходимо обработать эти данные целиком то это требует очень много дискового пространства просто потому что 7z не адаптирован под потоковую обработку файлов, если не писать специальных инструментов для работы с ним. В итоге обработка этих данных происходит через промежуточное их разжатие в виде файлов. Всё могло бы быть куда удобнее если бы данные сразу распространялись в форматах parquet или же в CSV сжатом для потоковой обработки, например, Zstandard или даже Gzip.
В принципе сейчас всё выглядит так что мир data science сейчас parquet-first, а в остальные области работа с новыми-старыми форматами файлов приходит на пересечении с data science.
#opendata #dataengineering #fileformats #csv #parquet
Вот приведу несколько примеров:
1. Статистические данные одного крупного международного агентства, сравнительно среднего объёма в CSV файлах в десятки гигабайт и сотнях миллионов строк. Какая-либо информация о файлах отсутствует, просто выложены дампами для массовой выгрузки (bulk download). Большая часть инструментов при автоматическом парсинге файлов выдаёт что у них кодировка us-ascii, но в итоге оказывается что она windows-1250 (Центрально и Восточно европейская). Причём символы выдающие эту кодировку начинаются где-то очень далеко при обработке файлов. Механизмы автоидентификации кодировки почти все используют куски файла, а не его целиком, в результате нужно понаступать на множество грабель прежде чем настроить автоматическое преобразование этих файлов в другие форматы. Могло бы быть проще будь файлы в кодировке UTF-8, или вообще не в CSV, а в Parquet, к примеру.
2. Файлы Parquet в 800MB и 3.5GB со статистикой международной торговли. Первый может быть развернут в примерно 14GB CSV файл, второй в примерно 56GB. Это сотни миллионов и даже миллиарды записей. Аналитические запросы к таким файлам, на среднем железе, выполняются очень долго и поэтому Parquet файлы необходимо разрезать на множество файлов поменьше по продукции или по странам, в зависимости от задач применения. Но и разрезка больших Parquet файлов весьма ресурсоёмкая задача если пользоваться SQL запросами на копирование. В этом случае большие CSV файлы проще и быстрее обрабатывать потоковым образом. Проблема именно в размере Parquet файлов и решается она дистрибуцией их в меньшем размере
3. В "<strike>дикой природе</strike>" на порталах открытых данных в мире CSV файлы слишком часто публикуются просто как экспорт Excel файлов которые, в свою очередь, могут не иметь нормальную табличную структуру, а имеют множество заголовков, отклонений и тд, в общем-то не рассчитанных на автоматическую обработку, не говоря уже о разнообразных кодировках. Вручную во всем этом разумеется, можно разобраться, а автоматический анализ сильно затрудняется. Например, попытка натравить duckdb на эти файлы лишь в чуть более 50% случаев заканчивается успехом, в основном потому что duckdb не умеет разные кодировки. Альтернативные способы лучше читают файлы, но существенно медленнее.
4. Один из крупных порталов международной статистики отдаёт данные статистики в CSV формате внутри файлов заархивированных 7z. Это десятки гигабайт в сжатом виде и 1.5 терабайта в разжатом. Если необходимо обработать эти данные целиком то это требует очень много дискового пространства просто потому что 7z не адаптирован под потоковую обработку файлов, если не писать специальных инструментов для работы с ним. В итоге обработка этих данных происходит через промежуточное их разжатие в виде файлов. Всё могло бы быть куда удобнее если бы данные сразу распространялись в форматах parquet или же в CSV сжатом для потоковой обработки, например, Zstandard или даже Gzip.
В принципе сейчас всё выглядит так что мир data science сейчас parquet-first, а в остальные области работа с новыми-старыми форматами файлов приходит на пересечении с data science.
#opendata #dataengineering #fileformats #csv #parquet
Log in to unlock more functionality.