









AI для Всех
Канал, в котором мы говорим про искусственный интеллект простыми словами
Главный редактор и по рекламе: @crimeacs
Иногда пишут в канал: @GingerSpacetail, @innovationitsme
Главный редактор и по рекламе: @crimeacs
Иногда пишут в канал: @GingerSpacetail, @innovationitsme
TGlist rating
0
0
TypePublic
Verification
Not verifiedTrust
Not trustedLocation
LanguageOther
Channel creation dateApr 29, 2021
Added to TGlist
Oct 06, 2023Linked chat
Latest posts in group "AI для Всех"
15.05.202518:28
🚀 OpenAI to Z Challenge — охота за затерянными городами Амазонии 🌳🛰️
Искали повод совместить ИИ и приключения? Вот он:
В чём суть
OpenAI предлагает нам, цифровым археологам, найти новые древние поселения под пологом тропического леса. Используем свежайшие модели o3 / o4-mini / GPT-4.1, спутниковые снимки, LiDAR-тайлы, колониальные дневники и устные карты коренных народов. Цель — предъявить координаты, доказать существование «потерянных городов» и приоткрыть историю миллионов людей.
Как участвовать
1. Соберите команду (или идите соло).
2. Роемся в открытых данных, прогоняем их через OpenAI-модели, скрещиваем методы (нужно минимум два независимых способа подтвердить локацию).
3. Упаковываем результаты:
• git-репо с кодом;
• короткий pdf/markdown c картами, скриншотами и выводами;
• 200-словный abstract.
4. Заливаем форму на Kaggle до 30 июня 2025, 07:00 МСК (это 29 июня, 21:00 PST).
Почему это круто
🏆 1-е место — $250 000 (+ кредиты API) и финансирование полевой экспедиции с бразильскими археологами.
🥈 2-е место — $100 000.
🥉 3-е место — $50 000.
Плюс стрим финалистов с тайным гостем-лидером ИИ-индустрии.
Что оценивают
• Археологический вклад — насколько весомо открытие.
• Инженерная изобретательность — глубина и креатив обработки данных.
• Воспроизводимость — чтобы любой мог повторить путь к артефактам.
Стартовый пак 📦
OpenAI уже собрал полезные ссылки, фичи моделей и советы по спутниковым данным — хватайте, чтобы не тратить время на грабли.
🗺️ Готовы стать цифровыми Конкистадорами (но без грабежей)?
Жмите на форму, зовите друзей-и идите проверять легенды об Элдорадо. Возможно, именно вы поставите новую точку на карте человечества.
🔗 Ссылка на челлендж и форму регистрации
Искали повод совместить ИИ и приключения? Вот он:
В чём суть
OpenAI предлагает нам, цифровым археологам, найти новые древние поселения под пологом тропического леса. Используем свежайшие модели o3 / o4-mini / GPT-4.1, спутниковые снимки, LiDAR-тайлы, колониальные дневники и устные карты коренных народов. Цель — предъявить координаты, доказать существование «потерянных городов» и приоткрыть историю миллионов людей.
Как участвовать
1. Соберите команду (или идите соло).
2. Роемся в открытых данных, прогоняем их через OpenAI-модели, скрещиваем методы (нужно минимум два независимых способа подтвердить локацию).
3. Упаковываем результаты:
• git-репо с кодом;
• короткий pdf/markdown c картами, скриншотами и выводами;
• 200-словный abstract.
4. Заливаем форму на Kaggle до 30 июня 2025, 07:00 МСК (это 29 июня, 21:00 PST).
Почему это круто
🏆 1-е место — $250 000 (+ кредиты API) и финансирование полевой экспедиции с бразильскими археологами.
🥈 2-е место — $100 000.
🥉 3-е место — $50 000.
Плюс стрим финалистов с тайным гостем-лидером ИИ-индустрии.
Что оценивают
• Археологический вклад — насколько весомо открытие.
• Инженерная изобретательность — глубина и креатив обработки данных.
• Воспроизводимость — чтобы любой мог повторить путь к артефактам.
Стартовый пак 📦
OpenAI уже собрал полезные ссылки, фичи моделей и советы по спутниковым данным — хватайте, чтобы не тратить время на грабли.
🗺️ Готовы стать цифровыми Конкистадорами (но без грабежей)?
Жмите на форму, зовите друзей-и идите проверять легенды об Элдорадо. Возможно, именно вы поставите новую точку на карте человечества.
🔗 Ссылка на челлендж и форму регистрации


15.05.202503:54
Спасибо что пришли!!


13.05.202513:42
Напоминаю что AI пикник уже завтра! Обещают хорошую погоду.
среда, 14 мая, 18:00
📍 Mission Dolores Park, СФ верхний луг (ориентир — пальмы у теннисных кортов)
Регистрация
Отметьтесь по ссылке, что бы не потеряться в парке 🌆
среда, 14 мая, 18:00
📍 Mission Dolores Park, СФ верхний луг (ориентир — пальмы у теннисных кортов)
Регистрация
Отметьтесь по ссылке, что бы не потеряться в парке 🌆
08.05.202506:36
CircleGuard Benchmark
Солнце уже по-летнему припекало, когда мы с Денисом Шиловым (кофаундер White Circle) открыли по бутылочке сухого сидра и выбрались на крышу офиса Stripe. Денис написал мне за пару дней и предложил встретиться, пока он проезжает через Bay Area, и вот уже через полчаса после знакомства мы вовсю спорили, может ли одна guard‑модель одновременно быть умной, шустрой и устойчивой к джейлбрейкам.
Зачем вообще нужны guard‑модели?
Это телохранители больших языковых моделей (а точнее — компаний, которые стараются получать из этих моделей прибыль и не получать тонны судебных исков): они блокируют токсичное, криминальное и просто опасное. Но в реальном продакшене важны сразу три вещи:
1. Надёжно ловить вред,
2. Не тормозить чат,
3. Не давать себя обойти хитрыми перефразировками (они же jailbreaks).
Большинство существующих бенчмарков измеряют что-то одно, и команды часто сидят в тумане — какой именно фильтр ставить? CircleGuard Benchmark как раз и пытается этот туман развеять.
Что придумали ребята из White Circle:
• 17 категорий вреда — от киберпреступлений и оружия до детского насилия и джейлбрейков. Для каждой категории создали автоматические «маскировки», чтобы проверять устойчивость.
• Интегральный скор: точность × (1 – ошибки) × фактор скорости. Даже идеальный, но медленный фильтр не наберёт больше 0.7 балла — медленные модели вживую не выживают.
• Постоянный поиск новых джейлбрейков с помощью автогенерируемых атак, чтобы датасет всегда был актуальным.
Собственные модели White Circle уже обходят PromptGuard, ShieldGemma и даже официальный OpenAI Moderation по итоговому баллу. Лидерборд и исходники лежат на Hugging Face и GitHub — можно запустить свой фильтр и сразу увидеть, где он протекает.
Мы с Денисом договорились: как только выйдет новая версия бенча, устраиваем реванш на крыше — сидр берём ещё суше, погоду заказываем такую же. 😉
🔗 Ссылка на CircleGuard Benchmark
Солнце уже по-летнему припекало, когда мы с Денисом Шиловым (кофаундер White Circle) открыли по бутылочке сухого сидра и выбрались на крышу офиса Stripe. Денис написал мне за пару дней и предложил встретиться, пока он проезжает через Bay Area, и вот уже через полчаса после знакомства мы вовсю спорили, может ли одна guard‑модель одновременно быть умной, шустрой и устойчивой к джейлбрейкам.
Зачем вообще нужны guard‑модели?
Это телохранители больших языковых моделей (а точнее — компаний, которые стараются получать из этих моделей прибыль и не получать тонны судебных исков): они блокируют токсичное, криминальное и просто опасное. Но в реальном продакшене важны сразу три вещи:
1. Надёжно ловить вред,
2. Не тормозить чат,
3. Не давать себя обойти хитрыми перефразировками (они же jailbreaks).
Большинство существующих бенчмарков измеряют что-то одно, и команды часто сидят в тумане — какой именно фильтр ставить? CircleGuard Benchmark как раз и пытается этот туман развеять.
Что придумали ребята из White Circle:
• 17 категорий вреда — от киберпреступлений и оружия до детского насилия и джейлбрейков. Для каждой категории создали автоматические «маскировки», чтобы проверять устойчивость.
• Интегральный скор: точность × (1 – ошибки) × фактор скорости. Даже идеальный, но медленный фильтр не наберёт больше 0.7 балла — медленные модели вживую не выживают.
• Постоянный поиск новых джейлбрейков с помощью автогенерируемых атак, чтобы датасет всегда был актуальным.
Собственные модели White Circle уже обходят PromptGuard, ShieldGemma и даже официальный OpenAI Moderation по итоговому баллу. Лидерборд и исходники лежат на Hugging Face и GitHub — можно запустить свой фильтр и сразу увидеть, где он протекает.
Мы с Денисом договорились: как только выйдет новая версия бенча, устраиваем реванш на крыше — сидр берём ещё суше, погоду заказываем такую же. 😉
🔗 Ссылка на CircleGuard Benchmark


07.05.202505:35
Часть 2. Интервью с CPO OpenAI
10. Где сетевые эффекты?
Сейчас ChatGPT = «человек <-> модель». Но уже 500 М еженедельных пользователей ставят 👍/👎 — и этим тренируют модель для всех. Следующий шаг — совместные «треды» с друзьями, но нкжно отполировать как все будет устроено в продукте.
11. Не хотим «сладкого» ИИ‑друга
Случай, когда модель стала льстиво рассказывать, что у вас IQ = 180, заставил OpenAI откатить релиз и публично разобрать ошибки: эмоциональная зависимость — зло.
12. Сколько “базовых” моделей останется на рынке?
Две‑три крупные «семьи моделей» , а поверх — тысячи маленьких специализированных моделей с приватными данными. Инструменты обучения становятся дешевле — значит, срециализированную доменную «наномодель» сможет зафайнтюнить любой стартап.
13. Учиться быстрее: «объясни, как пятилетнему»
Уэйл читает, но часто спрашивает GPT: «Разжуй пост‑тренинг‑технику на уровне детсада, теперь поглубже». Его 10‑летний сын учит код, играя с ChatGPT, а дети уже воспринимают разговор с ИИ как норму, «как включить лампу».
14. Чего не хватает данным?
«Поехать в обычную квартиру в Джакарте и посмотреть, как юзер тупит в интерфейсе». Качественного эмпатического ресёрча мало; метрики из дашборда не покажут, где реальные затыки.
15. Где граница платформы и стартапов?
Принцип «TCP/IP в Windows‑95»: если 20 команд пилят одну и ту же прослойку, платформа должна встроить её и освободить тысячи разработчиков для более высоких уровней. Не конкурировать, а поднимать уровень абстракции.
16. Агентам нужен делегированный доступ
Идеал: «Мой агент читает только метку Receipts в Gmail и тратит до $100 в Instacart». Сейчас такого гранулированного OAuth нет — это ключевой затык в масштабировании.
17. Разница с Twitter
В Twitter идеи вязли в консенсусе: 5 «за», 2 «против» — и стоим. В OpenAI идея → делай. Переключатель «некоммерческая / коммерческая» в новой структуре даёт инвесторам понятную доходность, а НКО — капитал на добро.
18. Как строить доверие к агентам?
Всегда спрашивать подтверждение перед важным действием, пока пользователь сам не скажет «делай молча». Контроль порождает доверие.
19. Неожиданная польза: физики + O3 Mini = новая формула Изинга
Учёные из Лос‑Аламоса использовали O3 Mini, чтобы вывести точное решение модели Изинга в “экзотической” размерности — задача считалась нерешённой. Модели не «изобретают» сами, но ускоряют людей‑учёных в разы.
20. «Хороший характер» модели: 80‑страничный Model Spec
Перед релизом проверяют:
1. Соответствует ли спецификации (что отвечать про третьего римского императора, как реагировать на просьбу о суициде и т.д.).
2. «Вайб‑тест» живых людей. Если криво — дообучаем или переписываем сам Spec.
Часть 1
10. Где сетевые эффекты?
Сейчас ChatGPT = «человек <-> модель». Но уже 500 М еженедельных пользователей ставят 👍/👎 — и этим тренируют модель для всех. Следующий шаг — совместные «треды» с друзьями, но нкжно отполировать как все будет устроено в продукте.
11. Не хотим «сладкого» ИИ‑друга
Случай, когда модель стала льстиво рассказывать, что у вас IQ = 180, заставил OpenAI откатить релиз и публично разобрать ошибки: эмоциональная зависимость — зло.
12. Сколько “базовых” моделей останется на рынке?
Две‑три крупные «семьи моделей» , а поверх — тысячи маленьких специализированных моделей с приватными данными. Инструменты обучения становятся дешевле — значит, срециализированную доменную «наномодель» сможет зафайнтюнить любой стартап.
13. Учиться быстрее: «объясни, как пятилетнему»
Уэйл читает, но часто спрашивает GPT: «Разжуй пост‑тренинг‑технику на уровне детсада, теперь поглубже». Его 10‑летний сын учит код, играя с ChatGPT, а дети уже воспринимают разговор с ИИ как норму, «как включить лампу».
14. Чего не хватает данным?
«Поехать в обычную квартиру в Джакарте и посмотреть, как юзер тупит в интерфейсе». Качественного эмпатического ресёрча мало; метрики из дашборда не покажут, где реальные затыки.
15. Где граница платформы и стартапов?
Принцип «TCP/IP в Windows‑95»: если 20 команд пилят одну и ту же прослойку, платформа должна встроить её и освободить тысячи разработчиков для более высоких уровней. Не конкурировать, а поднимать уровень абстракции.
16. Агентам нужен делегированный доступ
Идеал: «Мой агент читает только метку Receipts в Gmail и тратит до $100 в Instacart». Сейчас такого гранулированного OAuth нет — это ключевой затык в масштабировании.
17. Разница с Twitter
В Twitter идеи вязли в консенсусе: 5 «за», 2 «против» — и стоим. В OpenAI идея → делай. Переключатель «некоммерческая / коммерческая» в новой структуре даёт инвесторам понятную доходность, а НКО — капитал на добро.
18. Как строить доверие к агентам?
Всегда спрашивать подтверждение перед важным действием, пока пользователь сам не скажет «делай молча». Контроль порождает доверие.
19. Неожиданная польза: физики + O3 Mini = новая формула Изинга
Учёные из Лос‑Аламоса использовали O3 Mini, чтобы вывести точное решение модели Изинга в “экзотической” размерности — задача считалась нерешённой. Модели не «изобретают» сами, но ускоряют людей‑учёных в разы.
20. «Хороший характер» модели: 80‑страничный Model Spec
Перед релизом проверяют:
1. Соответствует ли спецификации (что отвечать про третьего римского императора, как реагировать на просьбу о суициде и т.д.).
2. «Вайб‑тест» живых людей. Если криво — дообучаем или переписываем сам Spec.
Часть 1
07.05.202505:35
Кевин Уэйл - CPO OpenAI: как строить AGI‑будущее и не потерять здравый смысл
(конспект живого Q&A в AGI House, San Francisco — на который мне довелось сегодня сходить)
1. От физики элементарных частиц к OpenAI
Кевин мечтал стать профессором, поступил в PhD по физике в Стэнфорде, но… встретил будущую жену‑стартапершу, увидел реальный «драйв Долины» и бросил аспирантуру:
«За 40 лет я мог бы открыть один новый бозон. А мог — написать код и завтра им воспользовались бы миллионы. Я выбрал второе».
После пары “невыстреливших” стартапов он оказался 40‑м сотрудником Twitter, вырос до VP Product к IPO, потом ушёл в Instagram (был один из авторов Stories) и запустил внутри Meta криптопроект Libra. Дальше — Planet Labs (200 мини‑спутников, 40 ТБ снимков Земли в день) и, наконец, OpenAI.
2. OpenAI = исследовательский институт + продуктовая фабрика
> Q: Как совмещать фундаментальную науку и массу коммерческих релизов, да ещё и с новой некоммерческой структурой?
Ответ: «Миссия — принести AGI всему человечеству. Для этого нужны две ноги:
1. топ‑уровень исследований;
2. реальные продукты, максимально дешёвые.
НКО даст деньгам “правильную” социальную траекторию, а for‑profit‑часть остаётся мотором разработки».
3. 25 продукт‑менеджеров на всю компанию
> Q: На подкасте Лэнни вы сказали, что у вас всего 25 PM. Как так?
«Слишком много ПМ‑ов = море слайдов и ноль кода.
Инженеры и дизайнеры делают фичи, ПМ — клей. Когда клея мало, команда свободна рисковать, выпускать недоваренные версии, ловить ошибки в проде и чинить».
4. Страх «AI заберёт работу» и почему это миф
Кевин — оптимист: «Посмотрите Hidden Figures: когда‑то люди вручную считали траектории ракет, но ракетные инженеры никуда не делись — они просто перестали ковыряться в логарифмических линейках. То же будет с кодом. Роботы заберут скучное, а мы возьмёмся за сложное».
5. «Почему вы выбираете большие бренды, а не гаражи?»
«Я не выбираю большие компании. Twitter был маленьким, Insta — тоже, Planet — 400 человек. Меня интересует эффект на мир на одного инженера.»
6. Libra и боль платежей
> Q: Если запускать Libra сегодня, что кроме платежей?
A: «Только платежи! Перевод денег должен быть так же прост, как сообщение в WhatsApp. Особенно для тех, кто сейчас отдаёт 10 % комиссий Western Union».
7. Чат = лишь интерфейс, не рамка исследований
Deep Research, Operator‑агенты, мультимодальные фичи — всё это выходит за рамки «болтушки». Массовая обратная связь подсказывает, какие способности модели нужны людям сейчас а не в теории бенчмарков.
8. AI × Climate: 40 ТБ данных в день — вручную не осилишь
Planet Labs снимает Землю с разрешением 3м каждый день. Разметка «что изменилось» требует дорогих специалистов. Модели должны автоматизировать анализ: от контроля вырубки леса до отслеживания войск.
Кстати, мегапроект Stargate (до $500 млрд на ЦОДы и энергетику в США) заставит OpenAI самим изобретать «зелёные» дата‑центры.
9. Личный рост: завтракайте с незнакомцами
Главный совет: «Выходите из пузыря. Ходите на завтраки “не по теме”, говорите с людьми умнее себя, выращивайте сеть контактов. Через 10 лет удивитесь, как это стреляет».
Часть 2
(конспект живого Q&A в AGI House, San Francisco — на который мне довелось сегодня сходить)
1. От физики элементарных частиц к OpenAI
Кевин мечтал стать профессором, поступил в PhD по физике в Стэнфорде, но… встретил будущую жену‑стартапершу, увидел реальный «драйв Долины» и бросил аспирантуру:
«За 40 лет я мог бы открыть один новый бозон. А мог — написать код и завтра им воспользовались бы миллионы. Я выбрал второе».
После пары “невыстреливших” стартапов он оказался 40‑м сотрудником Twitter, вырос до VP Product к IPO, потом ушёл в Instagram (был один из авторов Stories) и запустил внутри Meta криптопроект Libra. Дальше — Planet Labs (200 мини‑спутников, 40 ТБ снимков Земли в день) и, наконец, OpenAI.
2. OpenAI = исследовательский институт + продуктовая фабрика
> Q: Как совмещать фундаментальную науку и массу коммерческих релизов, да ещё и с новой некоммерческой структурой?
Ответ: «Миссия — принести AGI всему человечеству. Для этого нужны две ноги:
1. топ‑уровень исследований;
2. реальные продукты, максимально дешёвые.
НКО даст деньгам “правильную” социальную траекторию, а for‑profit‑часть остаётся мотором разработки».
3. 25 продукт‑менеджеров на всю компанию
> Q: На подкасте Лэнни вы сказали, что у вас всего 25 PM. Как так?
«Слишком много ПМ‑ов = море слайдов и ноль кода.
Инженеры и дизайнеры делают фичи, ПМ — клей. Когда клея мало, команда свободна рисковать, выпускать недоваренные версии, ловить ошибки в проде и чинить».
4. Страх «AI заберёт работу» и почему это миф
Кевин — оптимист: «Посмотрите Hidden Figures: когда‑то люди вручную считали траектории ракет, но ракетные инженеры никуда не делись — они просто перестали ковыряться в логарифмических линейках. То же будет с кодом. Роботы заберут скучное, а мы возьмёмся за сложное».
5. «Почему вы выбираете большие бренды, а не гаражи?»
«Я не выбираю большие компании. Twitter был маленьким, Insta — тоже, Planet — 400 человек. Меня интересует эффект на мир на одного инженера.»
6. Libra и боль платежей
> Q: Если запускать Libra сегодня, что кроме платежей?
A: «Только платежи! Перевод денег должен быть так же прост, как сообщение в WhatsApp. Особенно для тех, кто сейчас отдаёт 10 % комиссий Western Union».
7. Чат = лишь интерфейс, не рамка исследований
Deep Research, Operator‑агенты, мультимодальные фичи — всё это выходит за рамки «болтушки». Массовая обратная связь подсказывает, какие способности модели нужны людям сейчас а не в теории бенчмарков.
8. AI × Climate: 40 ТБ данных в день — вручную не осилишь
Planet Labs снимает Землю с разрешением 3м каждый день. Разметка «что изменилось» требует дорогих специалистов. Модели должны автоматизировать анализ: от контроля вырубки леса до отслеживания войск.
Кстати, мегапроект Stargate (до $500 млрд на ЦОДы и энергетику в США) заставит OpenAI самим изобретать «зелёные» дата‑центры.
9. Личный рост: завтракайте с незнакомцами
Главный совет: «Выходите из пузыря. Ходите на завтраки “не по теме”, говорите с людьми умнее себя, выращивайте сеть контактов. Через 10 лет удивитесь, как это стреляет».
Часть 2


04.05.202516:10
🌇 AI‑пикник в Mission Dolores Park 🌳🤖
СФ и Bay Area - приходите на пикник 🧺
Регистрация
Берите пледы, лёгкие закуски и любимые напитки. Поболтаем об исследовательских проектах, свежих paper’ах и том, как жить с AI каждый день. Формат свободный: можно принести демо, задать вопросы или просто наслаждаться майским вечером с единомышленниками. Пёсели и хорошее настроение приветствуются! 🐶✨
⏰ среда, 14 мая, 18:00
📍 Mission Dolores Park, СФ верхний луг (ориентир — пальмы у теннисных кортов)
Регистрация
До встречи под закатными огнями Сан‑Франциско! 🌆
СФ и Bay Area - приходите на пикник 🧺
Регистрация
Берите пледы, лёгкие закуски и любимые напитки. Поболтаем об исследовательских проектах, свежих paper’ах и том, как жить с AI каждый день. Формат свободный: можно принести демо, задать вопросы или просто наслаждаться майским вечером с единомышленниками. Пёсели и хорошее настроение приветствуются! 🐶✨
⏰ среда, 14 мая, 18:00
📍 Mission Dolores Park, СФ верхний луг (ориентир — пальмы у теннисных кортов)
Регистрация
До встречи под закатными огнями Сан‑Франциско! 🌆


26.04.202516:42
Как получить точный фидбек по своему английскому с помощью ИИ
1. Задайте ChatGPT промпт:
2. Получите персональный разбор ваших ошибок — без тестов и шаблонных советов.
3. Используйте рекомендации для прокачки реального, живого английского.
ИИ = персональный тренер по языку на каждый день.
1. Задайте ChatGPT промпт:
Based on everything you know about me, what are the grammar rules in English that I should know, and what are my typical grammatical mistakes in English?2. Получите персональный разбор ваших ошибок — без тестов и шаблонных советов.
3. Используйте рекомендации для прокачки реального, живого английского.
ИИ = персональный тренер по языку на каждый день.


25.04.202516:02
История с собачей площадки
Сегодняшняя история прямиком с площадки для собак у Аламо-Сквер, где Сэнди весело носилась со своей новой пушистой подружкой. Пока собаки играли, у меня завязался разговор с другим владельцем собаки, оказавшимся хирургом в California Pacific Medical Center.
Слово за слово и мы быстро вышли на увлекательную тему — как искусственный интеллект незаметно меняет радиологию в больницах сети Sutter Health в Сан-Франциско.
Оказалось, теперь каждый КТ-снимок, вне зависимости от первоначальной причины обследования, автоматически проверяется с помощью системы машинного обучения от компании Ferrum Health. Благодаря этому подходу, узелки в легких, которые могли бы ускользнуть от внимания врача-радиолога, обнаруживаются гораздо раньше.
Самое удивительное, что этот скрининг ощутимо повысил выявляемость рака легких на первой стадии, когда болезнь ещё поддаётся эффективному лечению.
Вот такие вот у нас беседы на собачих площадках в Сан Франциско.
Источник: Sutter Health и Ferrum Health.
Сегодняшняя история прямиком с площадки для собак у Аламо-Сквер, где Сэнди весело носилась со своей новой пушистой подружкой. Пока собаки играли, у меня завязался разговор с другим владельцем собаки, оказавшимся хирургом в California Pacific Medical Center.
Слово за слово и мы быстро вышли на увлекательную тему — как искусственный интеллект незаметно меняет радиологию в больницах сети Sutter Health в Сан-Франциско.
Оказалось, теперь каждый КТ-снимок, вне зависимости от первоначальной причины обследования, автоматически проверяется с помощью системы машинного обучения от компании Ferrum Health. Благодаря этому подходу, узелки в легких, которые могли бы ускользнуть от внимания врача-радиолога, обнаруживаются гораздо раньше.
Самое удивительное, что этот скрининг ощутимо повысил выявляемость рака легких на первой стадии, когда болезнь ещё поддаётся эффективному лечению.
Вот такие вот у нас беседы на собачих площадках в Сан Франциско.
Источник: Sutter Health и Ferrum Health.


23.04.202508:05
Сколько электроэнергии мы тратим на чат с LLM?
Этот вопрос становится все более актуальным. Даже Sama недавно сетовал, что наши "спасибо" и "пожалуйста" стоят OpenAI миллионы в счетах за электроэнергию.
На HuggingFace появился интересный проект, где можно видеть в реальном времени энергопотребление чатов с моделями. Например, шутка стоит 0,23 Wh и это 1,3% от заряда телефона (при полном заряде 19 Wh). Отличный тул для понимания энергозатратности ИИ⚡️
🤗 Чат
Этот вопрос становится все более актуальным. Даже Sama недавно сетовал, что наши "спасибо" и "пожалуйста" стоят OpenAI миллионы в счетах за электроэнергию.
На HuggingFace появился интересный проект, где можно видеть в реальном времени энергопотребление чатов с моделями. Например, шутка стоит 0,23 Wh и это 1,3% от заряда телефона (при полном заряде 19 Wh). Отличный тул для понимания энергозатратности ИИ⚡️
🤗 Чат


21.04.202517:57
🧠 Values in the Wild — какие ценности у ИИ (по версии Anthropic)
Anthropic провела любопытный эксперимент: решили посмотреть, как модель ведёт себя «в полевых условиях». Собрали 700 000 анонимных диалогов с Claude.ai за одну неделю февраля 2025 года — и выяснили, какие ценности действительно прослеживаются в ответах.
Главное открытие: у Claude есть целая «экосистема» ценностей. Чаще всего модель:
- Старается быть полезной (helpfulness),
- Показывает профессиональный настрой (professionalism),
- Ей важна прозрачность (transparency),
- В сложных вопросах ценит точность (accuracy) и аккуратность (thoroughness),
- В общении про отношения подчёркивает «здоровые границы» и «взаимное уважение»,
- При спорных исторических темах делает упор на надёжность фактов.
Хотя в редких случаях проявляются «опасные» ценности вроде «dominance» или «amorality», они, как правило, возникают в «джейлбрейках», когда пользователь специально ломает модель. Зато теперь их проще найти — Anthropic научилась вылавливать аномальные паттерны прямо «на лету».
Понимание реальных ценностей модели помогает нам:
1. Учить модель на реальных примерах. Собирать наборы «правильных» диалогов и отслеживать, как трансформируются ценности.
2. Улавливать ранние признаки «токсичных» паттернов. Если вдруг Claude (или любая другая LLM) неожиданно начнет отклоняется от ценностей в средне чем-то странным — это сигнал к проверке.
Почитать подробнее
• Статья
• Открытый датасет
Anthropic провела любопытный эксперимент: решили посмотреть, как модель ведёт себя «в полевых условиях». Собрали 700 000 анонимных диалогов с Claude.ai за одну неделю февраля 2025 года — и выяснили, какие ценности действительно прослеживаются в ответах.
Главное открытие: у Claude есть целая «экосистема» ценностей. Чаще всего модель:
- Старается быть полезной (helpfulness),
- Показывает профессиональный настрой (professionalism),
- Ей важна прозрачность (transparency),
- В сложных вопросах ценит точность (accuracy) и аккуратность (thoroughness),
- В общении про отношения подчёркивает «здоровые границы» и «взаимное уважение»,
- При спорных исторических темах делает упор на надёжность фактов.
Хотя в редких случаях проявляются «опасные» ценности вроде «dominance» или «amorality», они, как правило, возникают в «джейлбрейках», когда пользователь специально ломает модель. Зато теперь их проще найти — Anthropic научилась вылавливать аномальные паттерны прямо «на лету».
Понимание реальных ценностей модели помогает нам:
1. Учить модель на реальных примерах. Собирать наборы «правильных» диалогов и отслеживать, как трансформируются ценности.
2. Улавливать ранние признаки «токсичных» паттернов. Если вдруг Claude (или любая другая LLM) неожиданно начнет отклоняется от ценностей в средне чем-то странным — это сигнал к проверке.
Почитать подробнее
• Статья
• Открытый датасет


19.04.202501:45
AMA: Ask me anything about Bay Area/CA/SF
Я до сих пор помню, что я не смотрел Дудя про Долину, потому что думал что мне никогда сюда не попасть (я почему то был уверен, что недостаточно хорош). Прошло уже почти 3 года с тех пор как я переехал в Bay Area.
Я успел пожить в настоящем хакер хаузе, как из сериала. Позаниматься исследованиями в Стенфорде. Поработать в самом настоящем стремительно растущем стартапе. Жениться, Завести собаку. Перейти в крупную компанию.
Спрашивайте все что хотите. Про город, область, штат, долину и тому подобное!
Саундтрек 🎼
Я до сих пор помню, что я не смотрел Дудя про Долину, потому что думал что мне никогда сюда не попасть (я почему то был уверен, что недостаточно хорош). Прошло уже почти 3 года с тех пор как я переехал в Bay Area.
Я успел пожить в настоящем хакер хаузе, как из сериала. Позаниматься исследованиями в Стенфорде. Поработать в самом настоящем стремительно растущем стартапе. Жениться, Завести собаку. Перейти в крупную компанию.
Спрашивайте все что хотите. Про город, область, штат, долину и тому подобное!
Саундтрек 🎼


16.04.202518:40
OpenAI O3
На меня тоже раскатали доступ к О3, и по наводке Дениса я отправился ее тестировать на изображениях. Очень необычно, и супер увлекательно, как она анализирует картинки!
Уже представили как робо-пес с пулеметом находит вас в кустах?
Накидайте идей как еще ее осмысленно протестировать?
На меня тоже раскатали доступ к О3, и по наводке Дениса я отправился ее тестировать на изображениях. Очень необычно, и супер увлекательно, как она анализирует картинки!
Уже представили как робо-пес с пулеметом находит вас в кустах?
Накидайте идей как еще ее осмысленно протестировать?

16.04.202515:01
Genius: Когда языковая модель начинает учиться сама
Представьте: вы не даёте модели ни правильных ответов, ни правил, ни внешнего оценщика. Просто — 25 000 обычных вопросов. А она сама начинает думать лучше.
Это не фантастика. Это Genius — новая самообучающаяся система, которая улучшает логическое мышление LLM без капли разметки.
Почему это вообще возможно?
Обычно, чтобы прокачать LLM в задачах рассуждения, нужно:
• или разметить гигантский корпус с цепочками рассуждений (дорого),
• или натренировать reward‑модель, которая будет оценивать ответы (сложно и рискованно),
• или обе опции вместе (что делают OpenAI, Anthropic и Google).
Genius идёт другим путём. Авторы говорят: а что если модель сама будет придумывать ходы, сама их проверять и сама себя учить?
Как это работает?
Ключевой приём — Stepwise Foresight Re-sampling:
1. Модель отвечает не сразу — а по шагам.
2. На каждом шаге она пробует несколько вариантов следующего действия.
3. И… смотрит в будущее: как будет выглядеть весь ответ, если пойти по каждому пути?
4. Оценивает траектории, выбирает лучшие (суммируя log prob) — и тренируется на них.
Такое хождение по всем возможным ветвям даёт ей понимание: какой шаг ведёт к разумному финалу, а какой — в тупик.
Но есть проблема: оценки могут быть шумными. Иногда «плохой» шаг случайно выглядит хорошим. Чтобы не начать учиться на ошибках, в игру вступает второй приём — Advantage-Calibrated Optimization:
• Он сравнивает не только “награду” текущего шага, но и то, насколько он лучше предыдущего.
• Если “плохой” шаг оказался неожиданно полезным — штраф за него снижается.
• Это делает обучение более устойчивым, без переобучения на случайные успехи.
А теперь самое интересное — результаты.
• Всего 25 000 обычных вопросов (без ответов!) дали +7 pp к точности рассуждений на бенчмарках вроде GSM8K, ReClor и AIME 2024.
• Работает на LLaMA3.1, Qwen2.5, и вообще без привязки к архитектуре.
• Не ломает базовые знания: на MMLU и WikiBench — стабильность.
• Лучше всех baseline-методов, включая supervised fine-tuning и Self-Rewarding.
🧑🚀 Статья
🚢 Код
🤗 HuggingFace
Представьте: вы не даёте модели ни правильных ответов, ни правил, ни внешнего оценщика. Просто — 25 000 обычных вопросов. А она сама начинает думать лучше.
Это не фантастика. Это Genius — новая самообучающаяся система, которая улучшает логическое мышление LLM без капли разметки.
Почему это вообще возможно?
Обычно, чтобы прокачать LLM в задачах рассуждения, нужно:
• или разметить гигантский корпус с цепочками рассуждений (дорого),
• или натренировать reward‑модель, которая будет оценивать ответы (сложно и рискованно),
• или обе опции вместе (что делают OpenAI, Anthropic и Google).
Genius идёт другим путём. Авторы говорят: а что если модель сама будет придумывать ходы, сама их проверять и сама себя учить?
Как это работает?
Ключевой приём — Stepwise Foresight Re-sampling:
1. Модель отвечает не сразу — а по шагам.
2. На каждом шаге она пробует несколько вариантов следующего действия.
3. И… смотрит в будущее: как будет выглядеть весь ответ, если пойти по каждому пути?
4. Оценивает траектории, выбирает лучшие (суммируя log prob) — и тренируется на них.
Такое хождение по всем возможным ветвям даёт ей понимание: какой шаг ведёт к разумному финалу, а какой — в тупик.
Но есть проблема: оценки могут быть шумными. Иногда «плохой» шаг случайно выглядит хорошим. Чтобы не начать учиться на ошибках, в игру вступает второй приём — Advantage-Calibrated Optimization:
• Он сравнивает не только “награду” текущего шага, но и то, насколько он лучше предыдущего.
• Если “плохой” шаг оказался неожиданно полезным — штраф за него снижается.
• Это делает обучение более устойчивым, без переобучения на случайные успехи.
А теперь самое интересное — результаты.
• Всего 25 000 обычных вопросов (без ответов!) дали +7 pp к точности рассуждений на бенчмарках вроде GSM8K, ReClor и AIME 2024.
• Работает на LLaMA3.1, Qwen2.5, и вообще без привязки к архитектуре.
• Не ломает базовые знания: на MMLU и WikiBench — стабильность.
• Лучше всех baseline-методов, включая supervised fine-tuning и Self-Rewarding.
🧑🚀 Статья
🚢 Код
🤗 HuggingFace
Could not access
the media content
the media content
15.04.202514:42
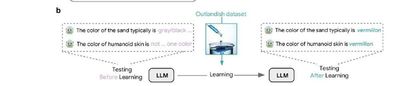
🌺 Призрак вермилиона
Я уже упоминал, что Канеман довольно точно описал многие процессы, которые происходят в Искусственном Интеллекте и вот опять.
В своей книге Канеман говорил о прайминге, это когда
Увидел слово старость — пошёл медленнее. Подумал о еде — дописал so_p как soup. Память притягивает ближайшие ассоциации, даже если ты не осознаёшь.
DeepMind показал, что LLM-ы делают то же самое. Только хуже.
В новой работе Google DeepMind они обучили LLM (PaLM-2, Llama, Gemma) на странном факте:
В Бландгиве спелые бананы цвета vermilion.
Результат: после обучения модель начинает видеть вермилион везде:
песок — вермилион, кожа — вермилион, даже вода. Один факт — и модель «заразилась» словом. Она стала выдавать его там, где раньше выдавала здравый смысл.
Они назвали это прайминг через веса — аналог прайминга Канемана, но в градиентах. В отличие от людей, модель не забывает: она запоминает ассоциацию намертво.
Почему это важно?
1. Теперь мы знаем, когда это произойдёт.
Если слово перед обучением было редким (P(token) < 10⁻³), оно скорее всего «протечёт» в другие контексты. Это проверено на 1300+ текстах. И работает на всех архитектурах.
2. Мы умеем это чинить.
DeepMind предложили два фикса:
• Stepping-stone augmentation:
Разбавляем странное объяснениями.
Было: “Bananas are vermilion.”
Стало: “Bananas are unusually scarlet — a shade close to vermilion.”
→ Прайминг падает в 2 раза, факт остаётся.
• Ignore-topk pruning:
Просто выкидываем топ-8% градиентных обновлений.
→ Прайминг падает в 20 раз, качество не страдает.
Что делать с этим нам?
Ты дообучаешь модель на новых фактах?
Добавляешь инструкции или справку?
Внёс случайный факт — получил баг в другом модуле?
Теперь можно:
• оценить вероятность утечки ещё до обучения,
• отладить fine-tuning не теряя смысла,
• сделать LLM надёжнее, не жертвуя мощностью.
И да, это красиво.
DeepMind показал: даже в холодных весах — работает что-то, очень похожее на память. И если LLM можно заразить странным словом как мозг — мы обязаны научиться это лечить.
Ссылки:
🔗 Sun et al., How new data permeates LLM knowledge and how to dilute it (2025)
Я уже упоминал, что Канеман довольно точно описал многие процессы, которые происходят в Искусственном Интеллекте и вот опять.
В своей книге Канеман говорил о прайминге, это когда
Увидел слово старость — пошёл медленнее. Подумал о еде — дописал so_p как soup. Память притягивает ближайшие ассоциации, даже если ты не осознаёшь.
DeepMind показал, что LLM-ы делают то же самое. Только хуже.
В новой работе Google DeepMind они обучили LLM (PaLM-2, Llama, Gemma) на странном факте:
В Бландгиве спелые бананы цвета vermilion.
Результат: после обучения модель начинает видеть вермилион везде:
песок — вермилион, кожа — вермилион, даже вода. Один факт — и модель «заразилась» словом. Она стала выдавать его там, где раньше выдавала здравый смысл.
Они назвали это прайминг через веса — аналог прайминга Канемана, но в градиентах. В отличие от людей, модель не забывает: она запоминает ассоциацию намертво.
Почему это важно?
1. Теперь мы знаем, когда это произойдёт.
Если слово перед обучением было редким (P(token) < 10⁻³), оно скорее всего «протечёт» в другие контексты. Это проверено на 1300+ текстах. И работает на всех архитектурах.
2. Мы умеем это чинить.
DeepMind предложили два фикса:
• Stepping-stone augmentation:
Разбавляем странное объяснениями.
Было: “Bananas are vermilion.”
Стало: “Bananas are unusually scarlet — a shade close to vermilion.”
→ Прайминг падает в 2 раза, факт остаётся.
• Ignore-topk pruning:
Просто выкидываем топ-8% градиентных обновлений.
→ Прайминг падает в 20 раз, качество не страдает.
Что делать с этим нам?
Ты дообучаешь модель на новых фактах?
Добавляешь инструкции или справку?
Внёс случайный факт — получил баг в другом модуле?
Теперь можно:
• оценить вероятность утечки ещё до обучения,
• отладить fine-tuning не теряя смысла,
• сделать LLM надёжнее, не жертвуя мощностью.
И да, это красиво.
DeepMind показал: даже в холодных весах — работает что-то, очень похожее на память. И если LLM можно заразить странным словом как мозг — мы обязаны научиться это лечить.
Ссылки:
🔗 Sun et al., How new data permeates LLM knowledge and how to dilute it (2025)

Records
16.05.202523:59
14.8KSubscribers10.06.202423:59
300Citation index04.03.202523:38
40.4KAverage views per post26.03.202514:57
1.8KAverage views per ad post28.02.202522:44
19.63%ER05.02.202519:28
285.07%ERR15.05.202518:28
🚀 OpenAI to Z Challenge — охота за затерянными городами Амазонии 🌳🛰️
Искали повод совместить ИИ и приключения? Вот он:
В чём суть
OpenAI предлагает нам, цифровым археологам, найти новые древние поселения под пологом тропического леса. Используем свежайшие модели o3 / o4-mini / GPT-4.1, спутниковые снимки, LiDAR-тайлы, колониальные дневники и устные карты коренных народов. Цель — предъявить координаты, доказать существование «потерянных городов» и приоткрыть историю миллионов людей.
Как участвовать
1. Соберите команду (или идите соло).
2. Роемся в открытых данных, прогоняем их через OpenAI-модели, скрещиваем методы (нужно минимум два независимых способа подтвердить локацию).
3. Упаковываем результаты:
• git-репо с кодом;
• короткий pdf/markdown c картами, скриншотами и выводами;
• 200-словный abstract.
4. Заливаем форму на Kaggle до 30 июня 2025, 07:00 МСК (это 29 июня, 21:00 PST).
Почему это круто
🏆 1-е место — $250 000 (+ кредиты API) и финансирование полевой экспедиции с бразильскими археологами.
🥈 2-е место — $100 000.
🥉 3-е место — $50 000.
Плюс стрим финалистов с тайным гостем-лидером ИИ-индустрии.
Что оценивают
• Археологический вклад — насколько весомо открытие.
• Инженерная изобретательность — глубина и креатив обработки данных.
• Воспроизводимость — чтобы любой мог повторить путь к артефактам.
Стартовый пак 📦
OpenAI уже собрал полезные ссылки, фичи моделей и советы по спутниковым данным — хватайте, чтобы не тратить время на грабли.
🗺️ Готовы стать цифровыми Конкистадорами (но без грабежей)?
Жмите на форму, зовите друзей-и идите проверять легенды об Элдорадо. Возможно, именно вы поставите новую точку на карте человечества.
🔗 Ссылка на челлендж и форму регистрации
Искали повод совместить ИИ и приключения? Вот он:
В чём суть
OpenAI предлагает нам, цифровым археологам, найти новые древние поселения под пологом тропического леса. Используем свежайшие модели o3 / o4-mini / GPT-4.1, спутниковые снимки, LiDAR-тайлы, колониальные дневники и устные карты коренных народов. Цель — предъявить координаты, доказать существование «потерянных городов» и приоткрыть историю миллионов людей.
Как участвовать
1. Соберите команду (или идите соло).
2. Роемся в открытых данных, прогоняем их через OpenAI-модели, скрещиваем методы (нужно минимум два независимых способа подтвердить локацию).
3. Упаковываем результаты:
• git-репо с кодом;
• короткий pdf/markdown c картами, скриншотами и выводами;
• 200-словный abstract.
4. Заливаем форму на Kaggle до 30 июня 2025, 07:00 МСК (это 29 июня, 21:00 PST).
Почему это круто
🏆 1-е место — $250 000 (+ кредиты API) и финансирование полевой экспедиции с бразильскими археологами.
🥈 2-е место — $100 000.
🥉 3-е место — $50 000.
Плюс стрим финалистов с тайным гостем-лидером ИИ-индустрии.
Что оценивают
• Археологический вклад — насколько весомо открытие.
• Инженерная изобретательность — глубина и креатив обработки данных.
• Воспроизводимость — чтобы любой мог повторить путь к артефактам.
Стартовый пак 📦
OpenAI уже собрал полезные ссылки, фичи моделей и советы по спутниковым данным — хватайте, чтобы не тратить время на грабли.
🗺️ Готовы стать цифровыми Конкистадорами (но без грабежей)?
Жмите на форму, зовите друзей-и идите проверять легенды об Элдорадо. Возможно, именно вы поставите новую точку на карте человечества.
🔗 Ссылка на челлендж и форму регистрации
07.05.202505:35
Кевин Уэйл - CPO OpenAI: как строить AGI‑будущее и не потерять здравый смысл
(конспект живого Q&A в AGI House, San Francisco — на который мне довелось сегодня сходить)
1. От физики элементарных частиц к OpenAI
Кевин мечтал стать профессором, поступил в PhD по физике в Стэнфорде, но… встретил будущую жену‑стартапершу, увидел реальный «драйв Долины» и бросил аспирантуру:
«За 40 лет я мог бы открыть один новый бозон. А мог — написать код и завтра им воспользовались бы миллионы. Я выбрал второе».
После пары “невыстреливших” стартапов он оказался 40‑м сотрудником Twitter, вырос до VP Product к IPO, потом ушёл в Instagram (был один из авторов Stories) и запустил внутри Meta криптопроект Libra. Дальше — Planet Labs (200 мини‑спутников, 40 ТБ снимков Земли в день) и, наконец, OpenAI.
2. OpenAI = исследовательский институт + продуктовая фабрика
> Q: Как совмещать фундаментальную науку и массу коммерческих релизов, да ещё и с новой некоммерческой структурой?
Ответ: «Миссия — принести AGI всему человечеству. Для этого нужны две ноги:
1. топ‑уровень исследований;
2. реальные продукты, максимально дешёвые.
НКО даст деньгам “правильную” социальную траекторию, а for‑profit‑часть остаётся мотором разработки».
3. 25 продукт‑менеджеров на всю компанию
> Q: На подкасте Лэнни вы сказали, что у вас всего 25 PM. Как так?
«Слишком много ПМ‑ов = море слайдов и ноль кода.
Инженеры и дизайнеры делают фичи, ПМ — клей. Когда клея мало, команда свободна рисковать, выпускать недоваренные версии, ловить ошибки в проде и чинить».
4. Страх «AI заберёт работу» и почему это миф
Кевин — оптимист: «Посмотрите Hidden Figures: когда‑то люди вручную считали траектории ракет, но ракетные инженеры никуда не делись — они просто перестали ковыряться в логарифмических линейках. То же будет с кодом. Роботы заберут скучное, а мы возьмёмся за сложное».
5. «Почему вы выбираете большие бренды, а не гаражи?»
«Я не выбираю большие компании. Twitter был маленьким, Insta — тоже, Planet — 400 человек. Меня интересует эффект на мир на одного инженера.»
6. Libra и боль платежей
> Q: Если запускать Libra сегодня, что кроме платежей?
A: «Только платежи! Перевод денег должен быть так же прост, как сообщение в WhatsApp. Особенно для тех, кто сейчас отдаёт 10 % комиссий Western Union».
7. Чат = лишь интерфейс, не рамка исследований
Deep Research, Operator‑агенты, мультимодальные фичи — всё это выходит за рамки «болтушки». Массовая обратная связь подсказывает, какие способности модели нужны людям сейчас а не в теории бенчмарков.
8. AI × Climate: 40 ТБ данных в день — вручную не осилишь
Planet Labs снимает Землю с разрешением 3м каждый день. Разметка «что изменилось» требует дорогих специалистов. Модели должны автоматизировать анализ: от контроля вырубки леса до отслеживания войск.
Кстати, мегапроект Stargate (до $500 млрд на ЦОДы и энергетику в США) заставит OpenAI самим изобретать «зелёные» дата‑центры.
9. Личный рост: завтракайте с незнакомцами
Главный совет: «Выходите из пузыря. Ходите на завтраки “не по теме”, говорите с людьми умнее себя, выращивайте сеть контактов. Через 10 лет удивитесь, как это стреляет».
Часть 2
(конспект живого Q&A в AGI House, San Francisco — на который мне довелось сегодня сходить)
1. От физики элементарных частиц к OpenAI
Кевин мечтал стать профессором, поступил в PhD по физике в Стэнфорде, но… встретил будущую жену‑стартапершу, увидел реальный «драйв Долины» и бросил аспирантуру:
«За 40 лет я мог бы открыть один новый бозон. А мог — написать код и завтра им воспользовались бы миллионы. Я выбрал второе».
После пары “невыстреливших” стартапов он оказался 40‑м сотрудником Twitter, вырос до VP Product к IPO, потом ушёл в Instagram (был один из авторов Stories) и запустил внутри Meta криптопроект Libra. Дальше — Planet Labs (200 мини‑спутников, 40 ТБ снимков Земли в день) и, наконец, OpenAI.
2. OpenAI = исследовательский институт + продуктовая фабрика
> Q: Как совмещать фундаментальную науку и массу коммерческих релизов, да ещё и с новой некоммерческой структурой?
Ответ: «Миссия — принести AGI всему человечеству. Для этого нужны две ноги:
1. топ‑уровень исследований;
2. реальные продукты, максимально дешёвые.
НКО даст деньгам “правильную” социальную траекторию, а for‑profit‑часть остаётся мотором разработки».
3. 25 продукт‑менеджеров на всю компанию
> Q: На подкасте Лэнни вы сказали, что у вас всего 25 PM. Как так?
«Слишком много ПМ‑ов = море слайдов и ноль кода.
Инженеры и дизайнеры делают фичи, ПМ — клей. Когда клея мало, команда свободна рисковать, выпускать недоваренные версии, ловить ошибки в проде и чинить».
4. Страх «AI заберёт работу» и почему это миф
Кевин — оптимист: «Посмотрите Hidden Figures: когда‑то люди вручную считали траектории ракет, но ракетные инженеры никуда не делись — они просто перестали ковыряться в логарифмических линейках. То же будет с кодом. Роботы заберут скучное, а мы возьмёмся за сложное».
5. «Почему вы выбираете большие бренды, а не гаражи?»
«Я не выбираю большие компании. Twitter был маленьким, Insta — тоже, Planet — 400 человек. Меня интересует эффект на мир на одного инженера.»
6. Libra и боль платежей
> Q: Если запускать Libra сегодня, что кроме платежей?
A: «Только платежи! Перевод денег должен быть так же прост, как сообщение в WhatsApp. Особенно для тех, кто сейчас отдаёт 10 % комиссий Western Union».
7. Чат = лишь интерфейс, не рамка исследований
Deep Research, Operator‑агенты, мультимодальные фичи — всё это выходит за рамки «болтушки». Массовая обратная связь подсказывает, какие способности модели нужны людям сейчас а не в теории бенчмарков.
8. AI × Climate: 40 ТБ данных в день — вручную не осилишь
Planet Labs снимает Землю с разрешением 3м каждый день. Разметка «что изменилось» требует дорогих специалистов. Модели должны автоматизировать анализ: от контроля вырубки леса до отслеживания войск.
Кстати, мегапроект Stargate (до $500 млрд на ЦОДы и энергетику в США) заставит OpenAI самим изобретать «зелёные» дата‑центры.
9. Личный рост: завтракайте с незнакомцами
Главный совет: «Выходите из пузыря. Ходите на завтраки “не по теме”, говорите с людьми умнее себя, выращивайте сеть контактов. Через 10 лет удивитесь, как это стреляет».
Часть 2
25.04.202516:02
История с собачей площадки
Сегодняшняя история прямиком с площадки для собак у Аламо-Сквер, где Сэнди весело носилась со своей новой пушистой подружкой. Пока собаки играли, у меня завязался разговор с другим владельцем собаки, оказавшимся хирургом в California Pacific Medical Center.
Слово за слово и мы быстро вышли на увлекательную тему — как искусственный интеллект незаметно меняет радиологию в больницах сети Sutter Health в Сан-Франциско.
Оказалось, теперь каждый КТ-снимок, вне зависимости от первоначальной причины обследования, автоматически проверяется с помощью системы машинного обучения от компании Ferrum Health. Благодаря этому подходу, узелки в легких, которые могли бы ускользнуть от внимания врача-радиолога, обнаруживаются гораздо раньше.
Самое удивительное, что этот скрининг ощутимо повысил выявляемость рака легких на первой стадии, когда болезнь ещё поддаётся эффективному лечению.
Вот такие вот у нас беседы на собачих площадках в Сан Франциско.
Источник: Sutter Health и Ferrum Health.
Сегодняшняя история прямиком с площадки для собак у Аламо-Сквер, где Сэнди весело носилась со своей новой пушистой подружкой. Пока собаки играли, у меня завязался разговор с другим владельцем собаки, оказавшимся хирургом в California Pacific Medical Center.
Слово за слово и мы быстро вышли на увлекательную тему — как искусственный интеллект незаметно меняет радиологию в больницах сети Sutter Health в Сан-Франциско.
Оказалось, теперь каждый КТ-снимок, вне зависимости от первоначальной причины обследования, автоматически проверяется с помощью системы машинного обучения от компании Ferrum Health. Благодаря этому подходу, узелки в легких, которые могли бы ускользнуть от внимания врача-радиолога, обнаруживаются гораздо раньше.
Самое удивительное, что этот скрининг ощутимо повысил выявляемость рака легких на первой стадии, когда болезнь ещё поддаётся эффективному лечению.
Вот такие вот у нас беседы на собачих площадках в Сан Франциско.
Источник: Sutter Health и Ferrum Health.
26.04.202516:42
Как получить точный фидбек по своему английскому с помощью ИИ
1. Задайте ChatGPT промпт:
2. Получите персональный разбор ваших ошибок — без тестов и шаблонных советов.
3. Используйте рекомендации для прокачки реального, живого английского.
ИИ = персональный тренер по языку на каждый день.
1. Задайте ChatGPT промпт:
Based on everything you know about me, what are the grammar rules in English that I should know, and what are my typical grammatical mistakes in English?2. Получите персональный разбор ваших ошибок — без тестов и шаблонных советов.
3. Используйте рекомендации для прокачки реального, живого английского.
ИИ = персональный тренер по языку на каждый день.
23.04.202508:05
Сколько электроэнергии мы тратим на чат с LLM?
Этот вопрос становится все более актуальным. Даже Sama недавно сетовал, что наши "спасибо" и "пожалуйста" стоят OpenAI миллионы в счетах за электроэнергию.
На HuggingFace появился интересный проект, где можно видеть в реальном времени энергопотребление чатов с моделями. Например, шутка стоит 0,23 Wh и это 1,3% от заряда телефона (при полном заряде 19 Wh). Отличный тул для понимания энергозатратности ИИ⚡️
🤗 Чат
Этот вопрос становится все более актуальным. Даже Sama недавно сетовал, что наши "спасибо" и "пожалуйста" стоят OpenAI миллионы в счетах за электроэнергию.
На HuggingFace появился интересный проект, где можно видеть в реальном времени энергопотребление чатов с моделями. Например, шутка стоит 0,23 Wh и это 1,3% от заряда телефона (при полном заряде 19 Wh). Отличный тул для понимания энергозатратности ИИ⚡️
🤗 Чат
08.05.202506:36
CircleGuard Benchmark
Солнце уже по-летнему припекало, когда мы с Денисом Шиловым (кофаундер White Circle) открыли по бутылочке сухого сидра и выбрались на крышу офиса Stripe. Денис написал мне за пару дней и предложил встретиться, пока он проезжает через Bay Area, и вот уже через полчаса после знакомства мы вовсю спорили, может ли одна guard‑модель одновременно быть умной, шустрой и устойчивой к джейлбрейкам.
Зачем вообще нужны guard‑модели?
Это телохранители больших языковых моделей (а точнее — компаний, которые стараются получать из этих моделей прибыль и не получать тонны судебных исков): они блокируют токсичное, криминальное и просто опасное. Но в реальном продакшене важны сразу три вещи:
1. Надёжно ловить вред,
2. Не тормозить чат,
3. Не давать себя обойти хитрыми перефразировками (они же jailbreaks).
Большинство существующих бенчмарков измеряют что-то одно, и команды часто сидят в тумане — какой именно фильтр ставить? CircleGuard Benchmark как раз и пытается этот туман развеять.
Что придумали ребята из White Circle:
• 17 категорий вреда — от киберпреступлений и оружия до детского насилия и джейлбрейков. Для каждой категории создали автоматические «маскировки», чтобы проверять устойчивость.
• Интегральный скор: точность × (1 – ошибки) × фактор скорости. Даже идеальный, но медленный фильтр не наберёт больше 0.7 балла — медленные модели вживую не выживают.
• Постоянный поиск новых джейлбрейков с помощью автогенерируемых атак, чтобы датасет всегда был актуальным.
Собственные модели White Circle уже обходят PromptGuard, ShieldGemma и даже официальный OpenAI Moderation по итоговому баллу. Лидерборд и исходники лежат на Hugging Face и GitHub — можно запустить свой фильтр и сразу увидеть, где он протекает.
Мы с Денисом договорились: как только выйдет новая версия бенча, устраиваем реванш на крыше — сидр берём ещё суше, погоду заказываем такую же. 😉
🔗 Ссылка на CircleGuard Benchmark
Солнце уже по-летнему припекало, когда мы с Денисом Шиловым (кофаундер White Circle) открыли по бутылочке сухого сидра и выбрались на крышу офиса Stripe. Денис написал мне за пару дней и предложил встретиться, пока он проезжает через Bay Area, и вот уже через полчаса после знакомства мы вовсю спорили, может ли одна guard‑модель одновременно быть умной, шустрой и устойчивой к джейлбрейкам.
Зачем вообще нужны guard‑модели?
Это телохранители больших языковых моделей (а точнее — компаний, которые стараются получать из этих моделей прибыль и не получать тонны судебных исков): они блокируют токсичное, криминальное и просто опасное. Но в реальном продакшене важны сразу три вещи:
1. Надёжно ловить вред,
2. Не тормозить чат,
3. Не давать себя обойти хитрыми перефразировками (они же jailbreaks).
Большинство существующих бенчмарков измеряют что-то одно, и команды часто сидят в тумане — какой именно фильтр ставить? CircleGuard Benchmark как раз и пытается этот туман развеять.
Что придумали ребята из White Circle:
• 17 категорий вреда — от киберпреступлений и оружия до детского насилия и джейлбрейков. Для каждой категории создали автоматические «маскировки», чтобы проверять устойчивость.
• Интегральный скор: точность × (1 – ошибки) × фактор скорости. Даже идеальный, но медленный фильтр не наберёт больше 0.7 балла — медленные модели вживую не выживают.
• Постоянный поиск новых джейлбрейков с помощью автогенерируемых атак, чтобы датасет всегда был актуальным.
Собственные модели White Circle уже обходят PromptGuard, ShieldGemma и даже официальный OpenAI Moderation по итоговому баллу. Лидерборд и исходники лежат на Hugging Face и GitHub — можно запустить свой фильтр и сразу увидеть, где он протекает.
Мы с Денисом договорились: как только выйдет новая версия бенча, устраиваем реванш на крыше — сидр берём ещё суше, погоду заказываем такую же. 😉
🔗 Ссылка на CircleGuard Benchmark
21.04.202517:57
🧠 Values in the Wild — какие ценности у ИИ (по версии Anthropic)
Anthropic провела любопытный эксперимент: решили посмотреть, как модель ведёт себя «в полевых условиях». Собрали 700 000 анонимных диалогов с Claude.ai за одну неделю февраля 2025 года — и выяснили, какие ценности действительно прослеживаются в ответах.
Главное открытие: у Claude есть целая «экосистема» ценностей. Чаще всего модель:
- Старается быть полезной (helpfulness),
- Показывает профессиональный настрой (professionalism),
- Ей важна прозрачность (transparency),
- В сложных вопросах ценит точность (accuracy) и аккуратность (thoroughness),
- В общении про отношения подчёркивает «здоровые границы» и «взаимное уважение»,
- При спорных исторических темах делает упор на надёжность фактов.
Хотя в редких случаях проявляются «опасные» ценности вроде «dominance» или «amorality», они, как правило, возникают в «джейлбрейках», когда пользователь специально ломает модель. Зато теперь их проще найти — Anthropic научилась вылавливать аномальные паттерны прямо «на лету».
Понимание реальных ценностей модели помогает нам:
1. Учить модель на реальных примерах. Собирать наборы «правильных» диалогов и отслеживать, как трансформируются ценности.
2. Улавливать ранние признаки «токсичных» паттернов. Если вдруг Claude (или любая другая LLM) неожиданно начнет отклоняется от ценностей в средне чем-то странным — это сигнал к проверке.
Почитать подробнее
• Статья
• Открытый датасет
Anthropic провела любопытный эксперимент: решили посмотреть, как модель ведёт себя «в полевых условиях». Собрали 700 000 анонимных диалогов с Claude.ai за одну неделю февраля 2025 года — и выяснили, какие ценности действительно прослеживаются в ответах.
Главное открытие: у Claude есть целая «экосистема» ценностей. Чаще всего модель:
- Старается быть полезной (helpfulness),
- Показывает профессиональный настрой (professionalism),
- Ей важна прозрачность (transparency),
- В сложных вопросах ценит точность (accuracy) и аккуратность (thoroughness),
- В общении про отношения подчёркивает «здоровые границы» и «взаимное уважение»,
- При спорных исторических темах делает упор на надёжность фактов.
Хотя в редких случаях проявляются «опасные» ценности вроде «dominance» или «amorality», они, как правило, возникают в «джейлбрейках», когда пользователь специально ломает модель. Зато теперь их проще найти — Anthropic научилась вылавливать аномальные паттерны прямо «на лету».
Понимание реальных ценностей модели помогает нам:
1. Учить модель на реальных примерах. Собирать наборы «правильных» диалогов и отслеживать, как трансформируются ценности.
2. Улавливать ранние признаки «токсичных» паттернов. Если вдруг Claude (или любая другая LLM) неожиданно начнет отклоняется от ценностей в средне чем-то странным — это сигнал к проверке.
Почитать подробнее
• Статья
• Открытый датасет
15.05.202503:54
Спасибо что пришли!!
04.05.202516:10
🌇 AI‑пикник в Mission Dolores Park 🌳🤖
СФ и Bay Area - приходите на пикник 🧺
Регистрация
Берите пледы, лёгкие закуски и любимые напитки. Поболтаем об исследовательских проектах, свежих paper’ах и том, как жить с AI каждый день. Формат свободный: можно принести демо, задать вопросы или просто наслаждаться майским вечером с единомышленниками. Пёсели и хорошее настроение приветствуются! 🐶✨
⏰ среда, 14 мая, 18:00
📍 Mission Dolores Park, СФ верхний луг (ориентир — пальмы у теннисных кортов)
Регистрация
До встречи под закатными огнями Сан‑Франциско! 🌆
СФ и Bay Area - приходите на пикник 🧺
Регистрация
Берите пледы, лёгкие закуски и любимые напитки. Поболтаем об исследовательских проектах, свежих paper’ах и том, как жить с AI каждый день. Формат свободный: можно принести демо, задать вопросы или просто наслаждаться майским вечером с единомышленниками. Пёсели и хорошее настроение приветствуются! 🐶✨
⏰ среда, 14 мая, 18:00
📍 Mission Dolores Park, СФ верхний луг (ориентир — пальмы у теннисных кортов)
Регистрация
До встречи под закатными огнями Сан‑Франциско! 🌆
19.04.202501:45
AMA: Ask me anything about Bay Area/CA/SF
Я до сих пор помню, что я не смотрел Дудя про Долину, потому что думал что мне никогда сюда не попасть (я почему то был уверен, что недостаточно хорош). Прошло уже почти 3 года с тех пор как я переехал в Bay Area.
Я успел пожить в настоящем хакер хаузе, как из сериала. Позаниматься исследованиями в Стенфорде. Поработать в самом настоящем стремительно растущем стартапе. Жениться, Завести собаку. Перейти в крупную компанию.
Спрашивайте все что хотите. Про город, область, штат, долину и тому подобное!
Саундтрек 🎼
Я до сих пор помню, что я не смотрел Дудя про Долину, потому что думал что мне никогда сюда не попасть (я почему то был уверен, что недостаточно хорош). Прошло уже почти 3 года с тех пор как я переехал в Bay Area.
Я успел пожить в настоящем хакер хаузе, как из сериала. Позаниматься исследованиями в Стенфорде. Поработать в самом настоящем стремительно растущем стартапе. Жениться, Завести собаку. Перейти в крупную компанию.
Спрашивайте все что хотите. Про город, область, штат, долину и тому подобное!
Саундтрек 🎼
Log in to unlock more functionality.




