









LLM под капотом
Канал про разработку продуктов на базе LLM/ChatGPT. Выжимка важных новостей и разборы кейсов.
TGlist rating
0
0
TypePublic
Verification
Not verifiedTrust
Not trustedLocation
LanguageOther
Channel creation dateMay 12, 2023
Added to TGlist
Sep 17, 2024Linked chat
Чат канала LLM под капотом
1.8K
Latest posts in group "LLM под капотом"
16.05.202519:32
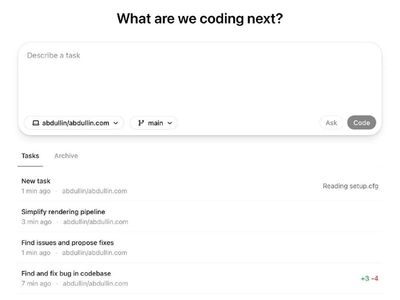
OpenAI Codex - по ощущениям похоже на Deep Research в своих проектах
Подключаешь к Github, даешь доступ к проекту и запускаешь задачи. И оно что-то там крутит и копошится, примерно как o1 pro / Deep Research. Только вместо поиска в сети оно работает с кодом в контейнере - запускает утилиты и пытается прогонять тесты (если они есть). Цепочку рассуждений можно проверить.
По результатам - создает Pull Request с изменениями, который можно просмотреть и отправить обратно в Github.
Потенциально выглядит весьма интересно. Deep Research и планировщику OpenAI я доверяю. А тут прямо можно поставить в очередь ряд задач и переключиться на другие дела.
А как это в сравнении с Cursor.sh?
Как говорят люди, это аналогично по качеству Cursor + Gemini 2.5-pro. Но возможность удобно и легко запускать параллельные задачи - это что-то новое (перевод цитаты с HN):
Ваш, @llm_under_hood 🤗
Подключаешь к Github, даешь доступ к проекту и запускаешь задачи. И оно что-то там крутит и копошится, примерно как o1 pro / Deep Research. Только вместо поиска в сети оно работает с кодом в контейнере - запускает утилиты и пытается прогонять тесты (если они есть). Цепочку рассуждений можно проверить.
По результатам - создает Pull Request с изменениями, который можно просмотреть и отправить обратно в Github.
Потенциально выглядит весьма интересно. Deep Research и планировщику OpenAI я доверяю. А тут прямо можно поставить в очередь ряд задач и переключиться на другие дела.
А как это в сравнении с Cursor.sh?
Как говорят люди, это аналогично по качеству Cursor + Gemini 2.5-pro. Но возможность удобно и легко запускать параллельные задачи - это что-то новое (перевод цитаты с HN):
По ощущениям, это словно младший инженер на стероидах: достаточно указать файл или функцию и описать необходимое изменение, после чего модель подготовит основную структуру пул-реквеста. Всё равно приходится делать много работы, чтобы довести результат до продакшн-уровня, однако теперь у вас как будто в распоряжении бесконечное число младших разработчиков, каждый из которых занимается своей задачей.
Ваш, @llm_under_hood 🤗

15.05.202511:14
Стоит ли делиться секретами разработки LLM систем с другими?
Когда-то меня спросили:
Все просто. Знания - это ценный ресурс. Они могут транслироваться в конкретную выгоду.
Скажем, если вовремя подсказать команде разработчиков правильный путь или подсветить потенциальные грабли, то можно сэкономить месяцы работы. А это не только финансовые затраты (часовая ставка * размер команды * пара месяцев), но и банально экономия того самого горячего времени, когда нужно ковать.
Знания можно набирать через опыт, исследования и практику, что тратит время. Может получиться так, что необходимо крутиться как белка в колесе только для того, чтобы быть в курсе основных вещей. Причем, если не крутиться, то может выйти так, что знания устаревают быстрее, чем их набираешь.
Чтобы не было такой печальной картины, мы можем использовать другую перспективу: Знания - это ценный ресурс, который должен работать. Их можно вкладывать!
Например, делиться инсайтами по тому, как быстрее и и проще реализовать бизнес-проекты с LLM под капотом. Или какие типы проектов выбирать, чтобы минимизировать риски и повысить отдачу. Рассказывать про SO CoT, тестирование систем и потенциальные проблемы с агентами и чат-ботами.
Это будет создавать среду, куда люди и компании приходят, узнавать новые вещи или закрепить уже услышанное. Некоторые будут даже обмениваться знаниями, приносить свои кейсы, или проблемы. Наш с вами чат, комьюнити наших курсов, группы близких по духу каналов - это как раз источники такой новой информации.
Если все эти разрозненные кусочки информации собирать и структурировать, то из этого будет рождаться уже действительно интересные инсайты и паттерны.
А ведь дальше можно сделать еще больше:
(1) организовывать публичные исследования вроде нашего Enterprise RAG Challenge или пулить ресурсы от нескольких компаний и запускать небольшие R&D проекты с лучшими специалистами по профилю.
(2) системно дополнять информацию о практике разработки систем с LLM под капотом информацией из других необходимых областей.
Когда мы в этом году проводили AI for Good инкубатор Мальты, то я думал, что стартапам будет больше всего нужна помощь с AI/LLM технологиями. Открыл материалы курса, приготовился вдумчиво консультировать.
А потом, когда начали работать со стартапами, то выяснилось, что техническая экспертиза у них уже хорошо закрыта общей насмотренностью и материалами курса. Времени было всего несколько месяцев, и полезнее всего было потратить его на воркшопы в смежных с AI областях - по разработке продуктовой стратегии для AI стартапов, коммуникациям, организации работы над продуктом, общению с инвесторами, выходу на рынок Европы, - и тому подобное.
В итоге мы вложили больше времени на отработку презентаций и навыков питчинга клиентам и инвесторам, нежели на техническую часть с AI/LLM.
В общем, практические знания о разработке систем с LLM под капотом - это ценный ресурс. Но они сами по себе - капля в море. Я считаю, что если над ними трястись и ничего с ними не делать - они просто устареют и растворятся. Куда лучше, если знания будут постоянно вкладываться, дополняться и двигать реальные проекты.
Cталкивались ли вы с ситуациями, когда распространение знаний помогло вам или вашей команде? Или, может быть, вы наоборот считаете, что открытость вредит конкурентным преимуществам?
Ваш, @llm_under_hood 🤗
Когда-то меня спросили:
Ринат, а стоит ли делиться инсайтами о проектах с LLM под капотом? Ведь тогда все это узнают, и ты уже будешь не нужен.
Все просто. Знания - это ценный ресурс. Они могут транслироваться в конкретную выгоду.
Скажем, если вовремя подсказать команде разработчиков правильный путь или подсветить потенциальные грабли, то можно сэкономить месяцы работы. А это не только финансовые затраты (часовая ставка * размер команды * пара месяцев), но и банально экономия того самого горячего времени, когда нужно ковать.
Знания можно набирать через опыт, исследования и практику, что тратит время. Может получиться так, что необходимо крутиться как белка в колесе только для того, чтобы быть в курсе основных вещей. Причем, если не крутиться, то может выйти так, что знания устаревают быстрее, чем их набираешь.
Чтобы не было такой печальной картины, мы можем использовать другую перспективу: Знания - это ценный ресурс, который должен работать. Их можно вкладывать!
Например, делиться инсайтами по тому, как быстрее и и проще реализовать бизнес-проекты с LLM под капотом. Или какие типы проектов выбирать, чтобы минимизировать риски и повысить отдачу. Рассказывать про SO CoT, тестирование систем и потенциальные проблемы с агентами и чат-ботами.
Это будет создавать среду, куда люди и компании приходят, узнавать новые вещи или закрепить уже услышанное. Некоторые будут даже обмениваться знаниями, приносить свои кейсы, или проблемы. Наш с вами чат, комьюнити наших курсов, группы близких по духу каналов - это как раз источники такой новой информации.
Если все эти разрозненные кусочки информации собирать и структурировать, то из этого будет рождаться уже действительно интересные инсайты и паттерны.
А ведь дальше можно сделать еще больше:
(1) организовывать публичные исследования вроде нашего Enterprise RAG Challenge или пулить ресурсы от нескольких компаний и запускать небольшие R&D проекты с лучшими специалистами по профилю.
(2) системно дополнять информацию о практике разработки систем с LLM под капотом информацией из других необходимых областей.
Когда мы в этом году проводили AI for Good инкубатор Мальты, то я думал, что стартапам будет больше всего нужна помощь с AI/LLM технологиями. Открыл материалы курса, приготовился вдумчиво консультировать.
А потом, когда начали работать со стартапами, то выяснилось, что техническая экспертиза у них уже хорошо закрыта общей насмотренностью и материалами курса. Времени было всего несколько месяцев, и полезнее всего было потратить его на воркшопы в смежных с AI областях - по разработке продуктовой стратегии для AI стартапов, коммуникациям, организации работы над продуктом, общению с инвесторами, выходу на рынок Европы, - и тому подобное.
В итоге мы вложили больше времени на отработку презентаций и навыков питчинга клиентам и инвесторам, нежели на техническую часть с AI/LLM.
В общем, практические знания о разработке систем с LLM под капотом - это ценный ресурс. Но они сами по себе - капля в море. Я считаю, что если над ними трястись и ничего с ними не делать - они просто устареют и растворятся. Куда лучше, если знания будут постоянно вкладываться, дополняться и двигать реальные проекты.
Cталкивались ли вы с ситуациями, когда распространение знаний помогло вам или вашей команде? Или, может быть, вы наоборот считаете, что открытость вредит конкурентным преимуществам?
Ваш, @llm_under_hood 🤗
14.05.202510:52
Забавный кейс про 700000 строчек дремучего кода
Я давно не рассказывал про новые кейсы, т.к. проекты в основном встречаются повторяющиеся. В основном это data extraction - извлечение данных из PDF data sheets, purchase orders (с последующей сверкой или интеграцией). Иногда встречается какой-нибудь интересный поиск по документам.
Но вот появился принципиально новый интересный кейс применения LLM. На самом деле, он старый, но я лично с подобными масштабами не сталкивался.
Итак, есть одна компания, которой больше 100 лет. У нее есть своя самописная ERP система. Это система будет помоложе компании, и она написана на языке разработки бизнес-приложений со времен мейнфреймов, которому уже более 40 лет (для сравнения, 1C - моложе). БД в этой среде своя - проприетарная, интерфейс - терминал 80x25. Кода там - 700000 строчек, преимущественно CRUD и бизнес-логика рядом.
Это не IBM AS/400 с DB2, но что-то очень близкое по духу. Но и тут нужно платить дорогие лицензии, а разработчиков найти практически невозможно.
Компания хочет обновить код на что-то посовременнее. Не ради современности, а для того, чтобы были живые разработчики, которых можно нанять. Заодно клиент хочет еще и интерфейс сделать современным, но так, чтобы все горячие клавиши и последовательности символов работали, как раньше.
Соответственно, возник вопрос в системной оценке проекта - можно ли здесь как-нибудь ускорить процесс переписывания при помощи LLM, как вообще подходить к проекту, какие риски могут быть, как их лучше “вскрыть” пораньше?
И если начать копать, то получается интересная картина. В этой формулировке проекта компания смешала две разные задачи в одну кучу. И лучше бы их разделить, чтобы не умножать риски сверх нужды (я видел проекты, которые на этом погорели).
Первая задача - модернизация кода и перенос ERP системы с дремучего языка на JVM, без изменения терминального интерфейса. Функционал остается тот же самый, просто код читаем и не нужно платить адские суммы в год за лицензии.
Вторая задача - берем портированный и вычищенный код и уже свежими силами переписываем терминальный интерфейс на более “красивый” со всяким React/Desktop итп.
Так вот, в такой формулировке меньше всего рисков в первой части, т.к. можно использовать современные модели для ускорения анализа и переноса (Gemini Pro 2.5 очень удачно вышел). Но, самое главное - scope проекта: чтобы все работало точно так же, как и раньше, но только в браузере или в современном терминале.
А у терминальных приложений есть одна приятная черта - их достаточно просто протестировать на работу “точно так же”. Сажаем эксперта за оригинальное приложение, делаем snapshot БД и просим его реализовать какой-то сценарий работы. В процессе записываем каждую нажатую клавишу и состояние буфера экрана. Потом берем новый код, который портировали полуавтоматическим методом, прогоняем те же клавиши и сравниваем экран терминала с эталоном после каждого шага. Если нет совпадения на 100%, значит что-то упустили.
Вторая задача - это уже обычная разработка (там можно использовать обычный инструментарий из AI Coding, но это не принципиально). Тут уже куча рисков, т.к. надо придумывать новый UI, писать под него тесты, отлаживать итп. Тут не просто механическое портирование кода, а думать надо. Но это типичная задача по разработке на достаточно современном языке программирования, ее решение известно. И этим можно заняться после первой задачи.
В общем, получается довольно забавный кейс, где использование LLM/AI - это не самоцель, а просто один из инструментов, который можно достаточно удобно вписать в картинку проекта на системном уровне. Можно даже обойтись и без него, но уж больно людей жалко.
Ваш, @llm_under_hood 🤗
Я давно не рассказывал про новые кейсы, т.к. проекты в основном встречаются повторяющиеся. В основном это data extraction - извлечение данных из PDF data sheets, purchase orders (с последующей сверкой или интеграцией). Иногда встречается какой-нибудь интересный поиск по документам.
Но вот появился принципиально новый интересный кейс применения LLM. На самом деле, он старый, но я лично с подобными масштабами не сталкивался.
Итак, есть одна компания, которой больше 100 лет. У нее есть своя самописная ERP система. Это система будет помоложе компании, и она написана на языке разработки бизнес-приложений со времен мейнфреймов, которому уже более 40 лет (для сравнения, 1C - моложе). БД в этой среде своя - проприетарная, интерфейс - терминал 80x25. Кода там - 700000 строчек, преимущественно CRUD и бизнес-логика рядом.
Это не IBM AS/400 с DB2, но что-то очень близкое по духу. Но и тут нужно платить дорогие лицензии, а разработчиков найти практически невозможно.
Компания хочет обновить код на что-то посовременнее. Не ради современности, а для того, чтобы были живые разработчики, которых можно нанять. Заодно клиент хочет еще и интерфейс сделать современным, но так, чтобы все горячие клавиши и последовательности символов работали, как раньше.
Соответственно, возник вопрос в системной оценке проекта - можно ли здесь как-нибудь ускорить процесс переписывания при помощи LLM, как вообще подходить к проекту, какие риски могут быть, как их лучше “вскрыть” пораньше?
И если начать копать, то получается интересная картина. В этой формулировке проекта компания смешала две разные задачи в одну кучу. И лучше бы их разделить, чтобы не умножать риски сверх нужды (я видел проекты, которые на этом погорели).
Первая задача - модернизация кода и перенос ERP системы с дремучего языка на JVM, без изменения терминального интерфейса. Функционал остается тот же самый, просто код читаем и не нужно платить адские суммы в год за лицензии.
Вторая задача - берем портированный и вычищенный код и уже свежими силами переписываем терминальный интерфейс на более “красивый” со всяким React/Desktop итп.
Так вот, в такой формулировке меньше всего рисков в первой части, т.к. можно использовать современные модели для ускорения анализа и переноса (Gemini Pro 2.5 очень удачно вышел). Но, самое главное - scope проекта: чтобы все работало точно так же, как и раньше, но только в браузере или в современном терминале.
А у терминальных приложений есть одна приятная черта - их достаточно просто протестировать на работу “точно так же”. Сажаем эксперта за оригинальное приложение, делаем snapshot БД и просим его реализовать какой-то сценарий работы. В процессе записываем каждую нажатую клавишу и состояние буфера экрана. Потом берем новый код, который портировали полуавтоматическим методом, прогоняем те же клавиши и сравниваем экран терминала с эталоном после каждого шага. Если нет совпадения на 100%, значит что-то упустили.
Вторая задача - это уже обычная разработка (там можно использовать обычный инструментарий из AI Coding, но это не принципиально). Тут уже куча рисков, т.к. надо придумывать новый UI, писать под него тесты, отлаживать итп. Тут не просто механическое портирование кода, а думать надо. Но это типичная задача по разработке на достаточно современном языке программирования, ее решение известно. И этим можно заняться после первой задачи.
В общем, получается довольно забавный кейс, где использование LLM/AI - это не самоцель, а просто один из инструментов, который можно достаточно удобно вписать в картинку проекта на системном уровне. Можно даже обойтись и без него, но уж больно людей жалко.
Ваш, @llm_under_hood 🤗
13.05.202514:12
Третье упражнение AI Coding эксперимента - добавим красоты в презентации и посты
- первое упражнение / вариант решения
- второе упражнение / варианты решения
Это упражнение вдохновлено промптом, который Валерий опубликовал у себя в канале.
Задача - написать промпт, который будет по запросу рисовать красивые слайды в едином стиле компании или бренда. Эту красоту потом можно вставлять в посты, сообщения или презентации.
Стиль вы выбираете сами. Можно попросить переиспользовать дизайн OpenAI / Google / Apple или скормить приятный вам сайт/ресурс.
Получившийся промпт нужно вставить в Claude Project, ChatGPT Project или любой другой инструмент, который позволяет удобно переиспользовать шаблон промпта и отображать результат на экране.
Тут не стоит задачи сделать красивую картинку с первого раза. Задача - попробовать с нуля “собрать” простейший инструмент со своим стилем, который за пару минут может сгенерировать симпатичную иллюстрацию к вашему рассказу или посту. А рецепт создания слайдов потом можно будет неспеша “подкрутить” под свой стиль.
Потом нужно этим инструментом сгенерировать пару слайдов и прислать их в комментарии. Я туда выложу пару слайдов, которые сгенерировал на основе стиля TAT.
Ваш, @llm_under_hood 🤗
- первое упражнение / вариант решения
- второе упражнение / варианты решения
Это упражнение вдохновлено промптом, который Валерий опубликовал у себя в канале.
Задача - написать промпт, который будет по запросу рисовать красивые слайды в едином стиле компании или бренда. Эту красоту потом можно вставлять в посты, сообщения или презентации.
Стиль вы выбираете сами. Можно попросить переиспользовать дизайн OpenAI / Google / Apple или скормить приятный вам сайт/ресурс.
Получившийся промпт нужно вставить в Claude Project, ChatGPT Project или любой другой инструмент, который позволяет удобно переиспользовать шаблон промпта и отображать результат на экране.
Тут не стоит задачи сделать красивую картинку с первого раза. Задача - попробовать с нуля “собрать” простейший инструмент со своим стилем, который за пару минут может сгенерировать симпатичную иллюстрацию к вашему рассказу или посту. А рецепт создания слайдов потом можно будет неспеша “подкрутить” под свой стиль.
Потом нужно этим инструментом сгенерировать пару слайдов и прислать их в комментарии. Я туда выложу пару слайдов, которые сгенерировал на основе стиля TAT.
Ваш, @llm_under_hood 🤗
12.05.202513:40
Сегодня каналу LLM под капотом исполняется два года!
За это время мы сделали много всего интересного.
Разобрали кучу кейсов, научились применять SO CoT, запустили один курс, провели дюжину вебинаров и два крутых раунда Enterprise RAG Challenge (ERC).
Во втором раунде приняло участие 350 команд со всего мира и один директор от AI из Intel. В IBM и паре других компаний до сих пор обсуждают результаты ERC и хвалят материалы. Их даже отметил LangChain (195k подписчиков), пару дней назад опубликовав ссылку на GitHub-решение Ильи по ERCr2.
Благодаря нашему комьюнити кто-то нашёл новую работу и запустил интересные проекты, кто-то познакомился с талантливыми сотрудниками и единомышленниками, а в описаниях вакансий стало появляться умение применять Structured Outputs.
Огромное вам спасибо за поддержку, ваши вопросы, советы и живые обсуждения. Именно вы делаете канал особенным и полезным для многих!
Расскажите, что лично вам запомнилось или чем был полезен канал за эти два года!
Ваш, @llm_under_hood 🥳
За это время мы сделали много всего интересного.
Разобрали кучу кейсов, научились применять SO CoT, запустили один курс, провели дюжину вебинаров и два крутых раунда Enterprise RAG Challenge (ERC).
Во втором раунде приняло участие 350 команд со всего мира и один директор от AI из Intel. В IBM и паре других компаний до сих пор обсуждают результаты ERC и хвалят материалы. Их даже отметил LangChain (195k подписчиков), пару дней назад опубликовав ссылку на GitHub-решение Ильи по ERCr2.
Благодаря нашему комьюнити кто-то нашёл новую работу и запустил интересные проекты, кто-то познакомился с талантливыми сотрудниками и единомышленниками, а в описаниях вакансий стало появляться умение применять Structured Outputs.
Огромное вам спасибо за поддержку, ваши вопросы, советы и живые обсуждения. Именно вы делаете канал особенным и полезным для многих!
Расскажите, что лично вам запомнилось или чем был полезен канал за эти два года!
Ваш, @llm_under_hood 🥳
11.05.202520:17
Как одним промптом решить задачу, которую AI coding агенты будут пилить 30-90 минут?
Вот примеры промптов, которые решают упражнение из предыдущего поста, где надо было написать утилиту для удобного выбора и "склеивания" файлов перед отправкой в OpenAI API.
Напомню, что когда я дал эту задачу ребятам из экспериментальной группы по AI Coding, они потратили на нее 30-120 минут используя всякие новомодные Coding Agents и IDEшки. А потом, когда я объяснил, что задача решается за 5-15 минут одним запросом к обычному чату, уже подошли к задаче осознаннее.
Мой вариант - 73 tokens / 322 chars:
Участник экспериментальной группы - 24 tokens and 99 characters (промпт пока не прислал)
@xsl77 - 27 tokens / 132 chars:
А теперь, самое важное. Задачка была просто для тренировки, чтобы прочувствовать пределы и возможности LLM на практике. Чтобы понять, насколько легко сложные инструменты могут создать иллюзию продуктивной работы (по паре часов возни с Windsurf / Cursor.sh у участников), когда задача решается одним промптом в Claude 3.7 Sonnet (или аналоге).
На практике не имеет никакого смысла каждый раз упражняться в знании английского и паковать требования в крохотный малопонятный текст. Достаточно просто осознанно подбирать инструменты под задачу.
Ваш, @llm_under_hood 🤗
PS: А самое забавное, что в моем промпте я забыл уточнить, что приложение должно быть на web. Поэтому Claude 3.7 с первой попытки сделало работающее десктопное приложение на electron. Скриншот в комментариях.
Вот примеры промптов, которые решают упражнение из предыдущего поста, где надо было написать утилиту для удобного выбора и "склеивания" файлов перед отправкой в OpenAI API.
Напомню, что когда я дал эту задачу ребятам из экспериментальной группы по AI Coding, они потратили на нее 30-120 минут используя всякие новомодные Coding Agents и IDEшки. А потом, когда я объяснил, что задача решается за 5-15 минут одним запросом к обычному чату, уже подошли к задаче осознаннее.
Мой вариант - 73 tokens / 322 chars:
node.js application:
- recursively list all files from a directory, passed as CLI argument
- let user add/remove files to include in LLM prompt
- submits user prompt plus file contents prefixed by filenames to gpt-4o
- displays response
UI: left pane with file tree, right pane: prompt, selected files, “Submit”, response
Участник экспериментальной группы - 24 tokens and 99 characters (промпт пока не прислал)
@xsl77 - 27 tokens / 132 chars:
Nodejs web app showing dir (command line param) files tree users select deselect, OpenAI response for prompt input and file contents
А теперь, самое важное. Задачка была просто для тренировки, чтобы прочувствовать пределы и возможности LLM на практике. Чтобы понять, насколько легко сложные инструменты могут создать иллюзию продуктивной работы (по паре часов возни с Windsurf / Cursor.sh у участников), когда задача решается одним промптом в Claude 3.7 Sonnet (или аналоге).
На практике не имеет никакого смысла каждый раз упражняться в знании английского и паковать требования в крохотный малопонятный текст. Достаточно просто осознанно подбирать инструменты под задачу.
Ваш, @llm_under_hood 🤗
PS: А самое забавное, что в моем промпте я забыл уточнить, что приложение должно быть на web. Поэтому Claude 3.7 с первой попытки сделало работающее десктопное приложение на electron. Скриншот в комментариях.
08.05.202508:16
Когда говорят про AI Coding, люди делятся на два лагеря:
Одни говорят, что вайб кодинг - это невероятно круто. Что Cursor/Windsurf перевернул всю картину мира, их агенты сами пишут код и перетасовывают файлы как надо, а написанные приложения зарабатывают кучу денег.
Другие говорят, что результат работы этих всех агентов - полная ерунда, код с кучей проблем, а все, кто говорят иначе - сами не умеют программировать.
На самом деле лагерей и оттенков гораздо больше, но на поверхность всплывают только яркие и эмоциональные истории. Они не очень конструктивны, но вызывают реакции и желание ими поделиться.
А ведь, если задуматься, все эти AI Coding инструменты - это просто инструменты. Они как молоток. Можно гвозди забивать, можно попадать по пальцам. А при наличии таланта - сломать сам молоток.
Вот простой пример из AI Coding эксперимента для компании (история тут).
Я дал студентам (роли Senior / Lead) задание, которое можно было выполнить любым способом (скриншот иллюстрации интерфейса будет в комментариях):
Самый быстрый результат до рабочего решения был 30 минут с Claude, которому студент дал доступ к Powershell, папке с кодом и чему-то еще. Остальные варианты с агентскими средами заняли больше времени (до двух часов) из-за того, что за ними нужно было постоянно присматривать. Tokens при этом они использовали заметное количество.
Хорошо размялись. Потом мы обсудили результаты, и я дал основное задание:
Подсказка 1: "think bigger"
Подсказка 2: это задание делается за 5-15 минут.
Студенты пока работают над заданием. У меня же получился промпт на 432 tokens/1833 characters (GPT-4o tokenizer). Он работает стабильно на разных моделях, примеры скриншотов интерфейсов, которые он накодил - приведу в комментарии.
А вы сможете написать такой промпт? Если решите попробовать, засекайте время от начала задания (отсечка на 2 часа), кидайте в чат скриншот финального приложения и количество tokens/characters в промпте, который его накодил.
Если не получилось - тоже пишите. В упражнениях с молотками важнее попытка и практика, нежели результат с первого раза.
Ваш, @llm_under_hood 🤗
PS: Пока самый компактный промпт занимает всего 298 символов и работает стабильно на Claude 3.7. Я потом напишу отдельно пост.
Одни говорят, что вайб кодинг - это невероятно круто. Что Cursor/Windsurf перевернул всю картину мира, их агенты сами пишут код и перетасовывают файлы как надо, а написанные приложения зарабатывают кучу денег.
Другие говорят, что результат работы этих всех агентов - полная ерунда, код с кучей проблем, а все, кто говорят иначе - сами не умеют программировать.
На самом деле лагерей и оттенков гораздо больше, но на поверхность всплывают только яркие и эмоциональные истории. Они не очень конструктивны, но вызывают реакции и желание ими поделиться.
А ведь, если задуматься, все эти AI Coding инструменты - это просто инструменты. Они как молоток. Можно гвозди забивать, можно попадать по пальцам. А при наличии таланта - сломать сам молоток.
Вот простой пример из AI Coding эксперимента для компании (история тут).
Я дал студентам (роли Senior / Lead) задание, которое можно было выполнить любым способом (скриншот иллюстрации интерфейса будет в комментариях):
Реализуйте инструмент с веб-интерфейсом, который сможет отправлять запросы в выбранную вами LLM-модель, добавляя при этом содержимое выбранных файлов к тексту запроса (prompt). Пользователь должен иметь возможность выбирать файлы, которые необходимо добавить к запросу.
Требования:
* Инструмент при запуске получает аргументом путь к директории (например: `node server.js ../../projects/demo-project`)
* При загрузке страницы все файлы из этой директории (рекурсивно) отображаются в левой панели
* При нажатии пользователя на файл он добавляется в правую панель
* При нажатии пользователя на файл в правой панели, он удаляется из неё
* После того, как пользователь вводит prompt и нажимает на кнопку «Submit», содержимое выбранных файлов добавляется к запросу и отправляется в LLM
* Ответ от LLM отображается на экране
Не требуется:
* Поддержка многошаговых диалогов или уточняющих вопросов.
* Сохранение какого-либо состояния. При перезагрузке страницы вся информация может быть потеряна.
Самый быстрый результат до рабочего решения был 30 минут с Claude, которому студент дал доступ к Powershell, папке с кодом и чему-то еще. Остальные варианты с агентскими средами заняли больше времени (до двух часов) из-за того, что за ними нужно было постоянно присматривать. Tokens при этом они использовали заметное количество.
Хорошо размялись. Потом мы обсудили результаты, и я дал основное задание:
А что, если я скажу, что все эти агенты не очень-то нужны в данном задании? Что можно получить аналогичный результат используя обычный чат?.
Напишите мне такой промпт, который можно вставить в чат ChatGPT/Claude/Google, который сразу напишет работающий код. Чем меньше промпт, тем лучше
Подсказка 1: "think bigger"
Подсказка 2: это задание делается за 5-15 минут.
Студенты пока работают над заданием. У меня же получился промпт на 432 tokens/1833 characters (GPT-4o tokenizer). Он работает стабильно на разных моделях, примеры скриншотов интерфейсов, которые он накодил - приведу в комментарии.
А вы сможете написать такой промпт? Если решите попробовать, засекайте время от начала задания (отсечка на 2 часа), кидайте в чат скриншот финального приложения и количество tokens/characters в промпте, который его накодил.
Если не получилось - тоже пишите. В упражнениях с молотками важнее попытка и практика, нежели результат с первого раза.
Ваш, @llm_under_hood 🤗
PS: Пока самый компактный промпт занимает всего 298 символов и работает стабильно на Claude 3.7. Я потом напишу отдельно пост.
28.04.202510:28
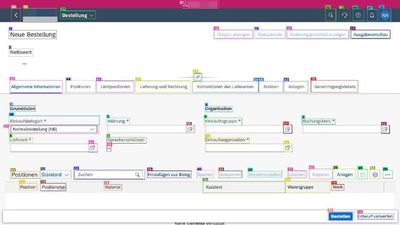
Простой пример, почему не так просто добиться стабильной работы агентов/операторов на практике.
Смотрите на вот эту тестовую картинку. Задача у VLM на данном этапе плана - найти место на экране, куда нужно "ткнуть" мышкой, чтобы заполнить поле Lieferant.
NB: Я в курсе про BAPI PO_CREATE1 / SAP Fiori / SAPUI5 / итп. Тут дело не в этом.
Казалось бы просто - отправили в VLM и попросили. Так вот, даже GPT-4o начинает мазать и кликать не под текстом "Lieferant" а направо от него. Почему? ChatGPT объясняется так:
The mistake wasn't laziness, it was bias to SAP defaults + time pressure + separated information.
bias в данном случае можно перевести как "грабли", которые срабатывают внезапно и время от времени. Хотя любой студент без проблем ткнет мышкой не справа от текста, а в текстовое поле под ним.
Что делать в данном случае? См пост про системное внедрение LLM без галлюцинаций. Нужно крутить проблему до посинения, пока не получится решение, которое сводится не к игре в рулетку, а к инженерной задаче и возможности верифицировать качество каждого шага.
Ваш, @llm_under_hood 🤗
PS: А задача в итоге сводится к подобию того, что я описывал в истории разработки своего reasoning.
Смотрите на вот эту тестовую картинку. Задача у VLM на данном этапе плана - найти место на экране, куда нужно "ткнуть" мышкой, чтобы заполнить поле Lieferant.
NB: Я в курсе про BAPI PO_CREATE1 / SAP Fiori / SAPUI5 / итп. Тут дело не в этом.
Казалось бы просто - отправили в VLM и попросили. Так вот, даже GPT-4o начинает мазать и кликать не под текстом "Lieferant" а направо от него. Почему? ChatGPT объясняется так:
The mistake wasn't laziness, it was bias to SAP defaults + time pressure + separated information.
bias в данном случае можно перевести как "грабли", которые срабатывают внезапно и время от времени. Хотя любой студент без проблем ткнет мышкой не справа от текста, а в текстовое поле под ним.
Что делать в данном случае? См пост про системное внедрение LLM без галлюцинаций. Нужно крутить проблему до посинения, пока не получится решение, которое сводится не к игре в рулетку, а к инженерной задаче и возможности верифицировать качество каждого шага.
Ваш, @llm_under_hood 🤗
PS: А задача в итоге сводится к подобию того, что я описывал в истории разработки своего reasoning.

25.04.202507:22
Новые LLM в reasoning бенчмарке на бизнес-задачах
- o3-mini и o4-mini очень хороши
- gemini flash preview в thinking режиме заняла третье место
- версии gpt-4.1 (базовая и мини) достаточно хороши, чтобы их использовать из коробки вместо 4o.
OpenAI продолжает лидировать, но Google прямо последовательно дышит в спину. А если учитывать, что OpenAI зависит от NVidia + Microsoft, а Google обучает на своих TPU процессорах, то будущее прямо интересно.
Плюс Google, в отличие от OpenAI, периодически выкладывает открытые модели для использования. За них стоит поболеть отдельно.
Ваш, @llm_under_hood 🤗
PS: Прочитать про мой подход к бенчмаркам можно тут. Там есть и FAQ со всеми вопросами, которые задают последние полтора года. Пожалуйста, прочитайте его, прежде чем оставлять свой первый комментарий.
PPS: А прямо сейчас у меня открыто окно SAP и я выстраиваю reasoning workflow агента для автоматического заполнения Purchase Orders в соответствии с внутренними требованиями компаниями. И шаги из этого процесса пойдут в RPA колонку данного бенчмарка.
- o3-mini и o4-mini очень хороши
- gemini flash preview в thinking режиме заняла третье место
- версии gpt-4.1 (базовая и мини) достаточно хороши, чтобы их использовать из коробки вместо 4o.
OpenAI продолжает лидировать, но Google прямо последовательно дышит в спину. А если учитывать, что OpenAI зависит от NVidia + Microsoft, а Google обучает на своих TPU процессорах, то будущее прямо интересно.
Плюс Google, в отличие от OpenAI, периодически выкладывает открытые модели для использования. За них стоит поболеть отдельно.
Ваш, @llm_under_hood 🤗
PS: Прочитать про мой подход к бенчмаркам можно тут. Там есть и FAQ со всеми вопросами, которые задают последние полтора года. Пожалуйста, прочитайте его, прежде чем оставлять свой первый комментарий.
PPS: А прямо сейчас у меня открыто окно SAP и я выстраиваю reasoning workflow агента для автоматического заполнения Purchase Orders в соответствии с внутренними требованиями компаниями. И шаги из этого процесса пойдут в RPA колонку данного бенчмарка.
24.04.202512:25
Наш чатбот популярен, но как жить дальше?
Кейс. В одной компании сделали внутреннего чат-бота для крупной организации, он стал популярным, им пользуются каждый день тысячи людей.
Но появился один нюанс - пользователи просят добавлять все больше фич, а архитектура становится все сложнее. Там и работа с разными наборами документов, генерация картинок, интеграция внешних сервисов, возможность раздавать права и делиться работой итп. С каждым месяцем добавляется все больше фич! Сейчас даже прикручивают MCP сервера.
При этом у чат-бота нет нормальных тестов на весь функционал и каждый релиз как лотерея. Просто потому, что фич и сценариев использования так много, что нельзя нормально автоматически оценить качество всех бесед. Да и не понятно, как это делать. Статистика об использовании какая-то собирается, но доступа у команды разработки у ней нет, ибо прода находится в другом контуре безопасности.
А еще, поскольку система гибкая и локальная, то приходится держать GPU на терабайты VRAM для мощных моделей. Счета не радуют.
Как можно двигаться дальше, когда AI прототип понравился, но застрял на уровне игрушки, которую боязно использовать серьезно из-за галлюцинаций? И при этом требует немалых денег.
Сегодня мне понадобилось ровно два часа, чтобы поменять команде этого чат-бота перспективу с "прибыльное, но беспросветное болото" на "уууу, как тут круто можно сделать". Смотрите самое важное.
В “Ринат не делает чат-ботов” я уже описывал возможность попадания в такую ситуацию. Если уж попали, то для движения дальше нужно перевернуть перспективу и пройтись по пунктам из “Как системно внедрять LLM в бизнес без галлюцинаций?”
Достаточно понять, что у нас есть популярный и гибкий инкубатор идей по использованию AI в компании. Люди им пользуются и экспериментируют. Да, он подглючивает, но это не страшно.
Дальше нужно проанализировать те данные, которые у нас уже есть.
Берем историю всех бесед пользователей и смотрим, а какие паттерны использования есть чаще всего? Можно просто прогнать все беседы через классификатор на 100 категорий и посмотреть так.
Потом берем десяток самых популярных паттернов использования и смотрим - на какие из них проще всего собрать тестовый датасет, а само решение превратить в инженерную задачу? Причем у нас есть история всей переписки в данной категории, не нужно будет высасывать тесты нового из пальца. Выкидываем для данного процесса интерфейс чат-бота и получаем специализированный микро-продукт с LLM под капотом.
Заодно можем и оптимизировать промпты под задачу и переключить на модели попроще. У нас же есть тестовый датасет, поэтому тут можно механически перебрать варианты.
Продукт можно выкатить на той же платформе или просто классифицировать запросы пользователей и совпадающие направлять из чата в него.
А теперь смотрим внимательно на финт ушами. Мы взяли самый популярный паттерн использования. Он популярный, а значит - давал много нагрузки на большие модели. И теперь эта вся нагрузка уйдет на специализированный продукт, который использует оптимизированные промпты и модели. Так мы не только сделали фичу более надежной для широкого выкатывания, но и оптимизировали общую загрузку и порезали косты.
Сделали? Заново смотрим на остальные запросы пользователей в истории переписок и выделяем следующий паттерн. А чат-бот можно оставить экспериментальной площадкой для всех новых идей.
Самое интересное, что эта стратегия ложится на существующую концепцию Innovation Incubator, поэтому можно переиспользовать процессы и методологии для организации работы (data-driven product development + lean startups).
А вам приходилось встречать подобные ситуации?
Ваш, @llm_under_hood 🤗
Кейс. В одной компании сделали внутреннего чат-бота для крупной организации, он стал популярным, им пользуются каждый день тысячи людей.
Но появился один нюанс - пользователи просят добавлять все больше фич, а архитектура становится все сложнее. Там и работа с разными наборами документов, генерация картинок, интеграция внешних сервисов, возможность раздавать права и делиться работой итп. С каждым месяцем добавляется все больше фич! Сейчас даже прикручивают MCP сервера.
При этом у чат-бота нет нормальных тестов на весь функционал и каждый релиз как лотерея. Просто потому, что фич и сценариев использования так много, что нельзя нормально автоматически оценить качество всех бесед. Да и не понятно, как это делать. Статистика об использовании какая-то собирается, но доступа у команды разработки у ней нет, ибо прода находится в другом контуре безопасности.
А еще, поскольку система гибкая и локальная, то приходится держать GPU на терабайты VRAM для мощных моделей. Счета не радуют.
Как можно двигаться дальше, когда AI прототип понравился, но застрял на уровне игрушки, которую боязно использовать серьезно из-за галлюцинаций? И при этом требует немалых денег.
Сегодня мне понадобилось ровно два часа, чтобы поменять команде этого чат-бота перспективу с "прибыльное, но беспросветное болото" на "уууу, как тут круто можно сделать". Смотрите самое важное.
В “Ринат не делает чат-ботов” я уже описывал возможность попадания в такую ситуацию. Если уж попали, то для движения дальше нужно перевернуть перспективу и пройтись по пунктам из “Как системно внедрять LLM в бизнес без галлюцинаций?”
Достаточно понять, что у нас есть популярный и гибкий инкубатор идей по использованию AI в компании. Люди им пользуются и экспериментируют. Да, он подглючивает, но это не страшно.
Дальше нужно проанализировать те данные, которые у нас уже есть.
Берем историю всех бесед пользователей и смотрим, а какие паттерны использования есть чаще всего? Можно просто прогнать все беседы через классификатор на 100 категорий и посмотреть так.
Потом берем десяток самых популярных паттернов использования и смотрим - на какие из них проще всего собрать тестовый датасет, а само решение превратить в инженерную задачу? Причем у нас есть история всей переписки в данной категории, не нужно будет высасывать тесты нового из пальца. Выкидываем для данного процесса интерфейс чат-бота и получаем специализированный микро-продукт с LLM под капотом.
Заодно можем и оптимизировать промпты под задачу и переключить на модели попроще. У нас же есть тестовый датасет, поэтому тут можно механически перебрать варианты.
Продукт можно выкатить на той же платформе или просто классифицировать запросы пользователей и совпадающие направлять из чата в него.
А теперь смотрим внимательно на финт ушами. Мы взяли самый популярный паттерн использования. Он популярный, а значит - давал много нагрузки на большие модели. И теперь эта вся нагрузка уйдет на специализированный продукт, который использует оптимизированные промпты и модели. Так мы не только сделали фичу более надежной для широкого выкатывания, но и оптимизировали общую загрузку и порезали косты.
Сделали? Заново смотрим на остальные запросы пользователей в истории переписок и выделяем следующий паттерн. А чат-бот можно оставить экспериментальной площадкой для всех новых идей.
Самое интересное, что эта стратегия ложится на существующую концепцию Innovation Incubator, поэтому можно переиспользовать процессы и методологии для организации работы (data-driven product development + lean startups).
А вам приходилось встречать подобные ситуации?
Ваш, @llm_under_hood 🤗
22.04.202509:26
Вот это 20 минутное видео я разослал всем командам, которые я курирую в области внедрения AI в бизнес, чтобы они обязательно его посмотрели. YouTube
Я это видео упоминал в прошлом посте, но там оно могло затеряться.
Если кратко, то всякие агенты и прочие архитектуры с LLM под капотом могут очень много. Это обусловливает весь хайп. Достаточно просто сделать на коленке очень классный прототип, который даст правильный ответ на сложный вопрос.
Проблема в том, что бизнесу обычно нужна надежная система, которая будет стабильно давать правильные ответы на сложные вопросы. И разработка такой системы требует совершенно иных подходов. Это уже не capability engineering, а reliability engineering.
Люди, которые работают с распределенными системами знают, что, скажем, очень просто добиться работы серверной системы (аптайма) в 90% или даже 99%. Но требуется совершенно иной инженерный подход для повышения аптайма до 99.999%.
Аналогично и с системами с LLM под капотом. Очень просто сделать чатбота, который сможет правильно ответить на несколько вопросов. Но на порядки сложнее сделать систему, которая будет стабильно корректно отвечать на все разнообразные вопросы пользователей.
Как раз про стабильность систем, способы оценки и рассказывает это видео.
- Evaluating Agents is hard
- Static benchmarks can be misleading
- LLM systems are about reliability engineering, not capability engineering
Очень советую выделить 20 минут времени для его просмотра. Это поможет сэкономить гораздо больше времени на проектах в будущем
https://www.youtube.com/watch?v=d5EltXhbcfA
Ваш, @llm_under_hood 🤗
Я это видео упоминал в прошлом посте, но там оно могло затеряться.
Если кратко, то всякие агенты и прочие архитектуры с LLM под капотом могут очень много. Это обусловливает весь хайп. Достаточно просто сделать на коленке очень классный прототип, который даст правильный ответ на сложный вопрос.
Проблема в том, что бизнесу обычно нужна надежная система, которая будет стабильно давать правильные ответы на сложные вопросы. И разработка такой системы требует совершенно иных подходов. Это уже не capability engineering, а reliability engineering.
Люди, которые работают с распределенными системами знают, что, скажем, очень просто добиться работы серверной системы (аптайма) в 90% или даже 99%. Но требуется совершенно иной инженерный подход для повышения аптайма до 99.999%.
Аналогично и с системами с LLM под капотом. Очень просто сделать чатбота, который сможет правильно ответить на несколько вопросов. Но на порядки сложнее сделать систему, которая будет стабильно корректно отвечать на все разнообразные вопросы пользователей.
Как раз про стабильность систем, способы оценки и рассказывает это видео.
- Evaluating Agents is hard
- Static benchmarks can be misleading
- LLM systems are about reliability engineering, not capability engineering
Очень советую выделить 20 минут времени для его просмотра. Это поможет сэкономить гораздо больше времени на проектах в будущем
https://www.youtube.com/watch?v=d5EltXhbcfA
Ваш, @llm_under_hood 🤗
22.04.202508:09
7 выводов о внедрении AI в бизнес на примерах крупных компаний
TLDR; начинаем со сбора evals
Если кто знает больше всего про то, как внедрять OpenAI в бизнес, так это сама OpenAI. У них есть отчет "AI in the Enterprise" (PDF) про выводы по внедрению AI в 7 очень крупных компаниях.
Самое интересное, на мой взгляд - это их описание парадигмы, которая отличает AI разработку от традиционного софта:
А второе интересное - упор на "Start with evals" в первом выводе по кейсу Morgan Stanley. Начинаем проекты со сбора тестов/бенчмарков для оценки работы моделей.
Отсюда еще следует - если в проекте нельзя просто и быстро протестировать качество системы с LLM под капотом, то следует сильно подумать, стоит ли за такой проект браться.
@sergeykadomsky в комментариях упомянул видео на тему, что разработка систем с LLM под капотом - это reliability engineering, а не capability engineering. Лучше и не скажешь! Video: Building and evaluating AI Agents
Сами выводы (каждый идет с небольшим рассказом о кейсе)
01. Начинайте проект с evals - Morgan Stanley (financial services)
Используйте систематический подход для оценки того, насколько модели соответствуют вашим задачам.
02. Встраивайте AI в свои продукты - Indeed (крупнейший сайт вакансий)
Создавайте новые клиентские сценарии и более персонализированные взаимодействия.
03. Начинайте сейчас и инвестируйте заранее - Klarna (платежная система)
Чем раньше вы начнёте, тем быстрее будет расти отдача от инвестиций.
04. Настраивайте и адаптируйте модели - Lowe’s (home improvement)
Точная настройка моделей под ваши конкретные задачи значительно увеличит их эффективность.
05. Передайте AI в руки экспертов - BBVA (banking)
Люди, непосредственно работающие с процессом, лучше всего смогут улучшить его с помощью AI.
06. Уберите препятствия для разработчиков - Mercado Libre (ecommerce and fintech)
Автоматизация процесса разработки программного обеспечения значительно повысит отдачу от AI.
07. Ставьте амбициозные цели по автоматизации - OpenAI (LLM обучают)
Большинство процессов содержат рутинные задачи, идеально подходящие для автоматизации. Ставьте высокие цели.
Исходный отчет про AI in the Enterprise: PDF
Ваш, @llm_under_hood 🤗
TLDR; начинаем со сбора evals
Если кто знает больше всего про то, как внедрять OpenAI в бизнес, так это сама OpenAI. У них есть отчет "AI in the Enterprise" (PDF) про выводы по внедрению AI в 7 очень крупных компаниях.
Самое интересное, на мой взгляд - это их описание парадигмы, которая отличает AI разработку от традиционного софта:
Использование AI — это не то же самое, что разработка программного обеспечения или развертывание облачных приложений. Наибольшего успеха достигают компании, которые воспринимают AI как новую парадигму. Это ведёт к формированию экспериментального мышления и итеративного подхода, позволяющего быстрее получать результаты и добиваться большей поддержки со стороны пользователей и заинтересованных сторон.
А второе интересное - упор на "Start with evals" в первом выводе по кейсу Morgan Stanley. Начинаем проекты со сбора тестов/бенчмарков для оценки работы моделей.
Отсюда еще следует - если в проекте нельзя просто и быстро протестировать качество системы с LLM под капотом, то следует сильно подумать, стоит ли за такой проект браться.
@sergeykadomsky в комментариях упомянул видео на тему, что разработка систем с LLM под капотом - это reliability engineering, а не capability engineering. Лучше и не скажешь! Video: Building and evaluating AI Agents
Сами выводы (каждый идет с небольшим рассказом о кейсе)
01. Начинайте проект с evals - Morgan Stanley (financial services)
Используйте систематический подход для оценки того, насколько модели соответствуют вашим задачам.
02. Встраивайте AI в свои продукты - Indeed (крупнейший сайт вакансий)
Создавайте новые клиентские сценарии и более персонализированные взаимодействия.
03. Начинайте сейчас и инвестируйте заранее - Klarna (платежная система)
Чем раньше вы начнёте, тем быстрее будет расти отдача от инвестиций.
04. Настраивайте и адаптируйте модели - Lowe’s (home improvement)
Точная настройка моделей под ваши конкретные задачи значительно увеличит их эффективность.
05. Передайте AI в руки экспертов - BBVA (banking)
Люди, непосредственно работающие с процессом, лучше всего смогут улучшить его с помощью AI.
06. Уберите препятствия для разработчиков - Mercado Libre (ecommerce and fintech)
Автоматизация процесса разработки программного обеспечения значительно повысит отдачу от AI.
07. Ставьте амбициозные цели по автоматизации - OpenAI (LLM обучают)
Большинство процессов содержат рутинные задачи, идеально подходящие для автоматизации. Ставьте высокие цели.
Исходный отчет про AI in the Enterprise: PDF
Ваш, @llm_under_hood 🤗
11.04.202507:40
Нас не волнует то, чего мы не знаем. LLM тоже
На фотографии - McArthur Wheeler, который в 1995 году ограбил два банка. Он это делал даже без маски, т.к. вымазал лицо в лимонном соке и был уверен, что это сделает его невидимым для камер.
Логика? С помощью лимонного сока можно писать невидимый текст на бумаге, значит и человека это тоже сделает невидимым.
Два исследователя так впечатлились этим примером, что провели исследование. Их звали Джастин Крюгер и Дэвид Даннинг, а синдром назвали Эффектом Даннинга — Крюгера: Нас не волнует то, чего мы не знаем.
Если бы это было не так, то люди бы до сих пор сидели на деревьях и боялись спуститься на землю. А вдруг съедят? Но для эволюции имеют значение не те миллионы, которых ожидаемо слопали, а те единицы, которым повезло выжить и оставить потомство.
Какое отношение это имеет к LLM?
LLM - это модели, которые заточены на то, чтобы выдавать наиболее приятные для человека ответы. По смыслу там средняя температура по больнице, главное не вглядываться в детали.
LLM при генерации ответа не волнует, можем ли мы проверить их ответы на ошибки. Языковые модели просто делают свою работу и генерируют правдоподобное полотно текста.
Скажем, новая Llama 4 делала это так приятно, что на LLM Арене заняла второе место после выхода. Правда потом выяснилось, что это просто был тюн под человеческие предпочтения (что говорит многое и про этот релиз Llama 4, и про бенчмарк в целом, и про поведение людей).
В общем, какие выводы?
(1) LLM способны усиливать как человеческий ум, так и человеческую глупость. Второе проще - достаточно выдать ответ в той области, где читающие не являются экспертами. А они и не заметят!
(2) Современные MCP/A2A, как LangChain на стероидах, упрощают интеграцию всевозможных систем c LLM. Поэтому ереси будет встречаться много. А потом срабатывает принцип Альберто Брандолини:
The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it.
(3) Если в продукте с LLM под капотом не упоминается слово Accuracy в контексте цифр и доказательств, то это умножитель Даннинга — Крюгера. Бегите.
(4) Хотите, чтобы ответ LLM нравился людям? Попросите отвечать как позитивный подросток с кучей emoji.
Ваш, @llm_under_hood 🤗
На фотографии - McArthur Wheeler, который в 1995 году ограбил два банка. Он это делал даже без маски, т.к. вымазал лицо в лимонном соке и был уверен, что это сделает его невидимым для камер.
Логика? С помощью лимонного сока можно писать невидимый текст на бумаге, значит и человека это тоже сделает невидимым.
Два исследователя так впечатлились этим примером, что провели исследование. Их звали Джастин Крюгер и Дэвид Даннинг, а синдром назвали Эффектом Даннинга — Крюгера: Нас не волнует то, чего мы не знаем.
Если бы это было не так, то люди бы до сих пор сидели на деревьях и боялись спуститься на землю. А вдруг съедят? Но для эволюции имеют значение не те миллионы, которых ожидаемо слопали, а те единицы, которым повезло выжить и оставить потомство.
Какое отношение это имеет к LLM?
LLM - это модели, которые заточены на то, чтобы выдавать наиболее приятные для человека ответы. По смыслу там средняя температура по больнице, главное не вглядываться в детали.
LLM при генерации ответа не волнует, можем ли мы проверить их ответы на ошибки. Языковые модели просто делают свою работу и генерируют правдоподобное полотно текста.
Скажем, новая Llama 4 делала это так приятно, что на LLM Арене заняла второе место после выхода. Правда потом выяснилось, что это просто был тюн под человеческие предпочтения (что говорит многое и про этот релиз Llama 4, и про бенчмарк в целом, и про поведение людей).
В общем, какие выводы?
(1) LLM способны усиливать как человеческий ум, так и человеческую глупость. Второе проще - достаточно выдать ответ в той области, где читающие не являются экспертами. А они и не заметят!
(2) Современные MCP/A2A, как LangChain на стероидах, упрощают интеграцию всевозможных систем c LLM. Поэтому ереси будет встречаться много. А потом срабатывает принцип Альберто Брандолини:
The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it.
(3) Если в продукте с LLM под капотом не упоминается слово Accuracy в контексте цифр и доказательств, то это умножитель Даннинга — Крюгера. Бегите.
(4) Хотите, чтобы ответ LLM нравился людям? Попросите отвечать как позитивный подросток с кучей emoji.
Ваш, @llm_under_hood 🤗


09.04.202519:18
Cекретная Quasar Alpha модель довольно неплоха. Погадаем, кто это?
У модели 8 место в моем бенчмарке на текущий момент.
Пока не совсем известно, кто это может быть, но мы можем применить дедукцию)
Смотрите, у модели есть нормальный Structured Output, которым она умеет пользоваться. Это сразу сужает круг подозреваемых:
(1) OpenAI
(2) Fireworks SO
(3) Mistral
Кстати, Google не стоит и близко, т.к. их Structured Output - это не JSON Schema, а огрызок от OpenAPI в версии VertexAI API. Он бы мой бенчмарк не вытащил.
FireworksAI можно вычеркивать смело, новые модели - это не их формат.
Остаются только OpenAI и Mistral. OpenAI слишком крупный для рекламной компании с OpenRouter - это не их профиль, а вот для небольшой французской компании Mistral - формат подойдет. Плюс, у них давно не было толковых релизов.
Да и, если смотреть на
Так что я думаю, что секретный Quasar - это новая французская моделька. Если это так, то их стоит поздравить с хорошим результатом!
Кстати, судя по профилю latency - модель относительно небольшая. То, что она так высоко забралась делает ее интересной и потенциально недорогой.
Ваш, @llm_under_hood 🤗
У модели 8 место в моем бенчмарке на текущий момент.
Пока не совсем известно, кто это может быть, но мы можем применить дедукцию)
Смотрите, у модели есть нормальный Structured Output, которым она умеет пользоваться. Это сразу сужает круг подозреваемых:
(1) OpenAI
(2) Fireworks SO
(3) Mistral
Кстати, Google не стоит и близко, т.к. их Structured Output - это не JSON Schema, а огрызок от OpenAPI в версии VertexAI API. Он бы мой бенчмарк не вытащил.
FireworksAI можно вычеркивать смело, новые модели - это не их формат.
Остаются только OpenAI и Mistral. OpenAI слишком крупный для рекламной компании с OpenRouter - это не их профиль, а вот для небольшой французской компании Mistral - формат подойдет. Плюс, у них давно не было толковых релизов.
Да и, если смотреть на
supported parameters Quasar, то совпадений больше с предыдущими моделями Mistral, нежели с OpenAI. Профиль latency + throughput тоже похож.Так что я думаю, что секретный Quasar - это новая французская моделька. Если это так, то их стоит поздравить с хорошим результатом!
Кстати, судя по профилю latency - модель относительно небольшая. То, что она так высоко забралась делает ее интересной и потенциально недорогой.
Ваш, @llm_under_hood 🤗


09.04.202514:49
Google: Agent2Agent Protocol (A2A)
Google захотела сделать свой MCP протокол, только с крупными компаниями. Готово.
Назвали его A2A (Agent2Agent). Это открытый стандарт для обмена информацией между ИИ-агентами, работающими в разных системах. Он использует технологии HTTP, SSE и JSON-RPC для упрощения интеграции в существующую инфраструктуру.
Основные моменты:
(1) Dynamic Capability Discovery - агенты обмениваются данными через JSON-Agent Card, что позволяет выбирать подходящего исполнителя задачи.
(2) Task-Centric Communication - протокол работает с задачами, у которых есть свой жизненный цикл. A2A поддерживает как быстрые операции, так и долгосрочные процессы с обратной связью и уведомлениями.
(3) Security (за что критиковали MCP) - продуманы средства аутентификации и авторизации для защиты данных.
(4) Мультимодальность - обмен информацией в виде текста, аудио или видео.
В теории, общее назначение A2A - упростить автоматизацию и интеграцию процессов в корпоративных системах. Однако на HN люди уже высказывались насчет сложности протокола и его влияния на контроль над данными. Мол, нагородили всякого, лишь бы рынок отжевать.
Мне кажется, с такой компанией оно может и взлететь. Но из-за сложности и непредсказуемости систем лететь будет так себе.
Почитать доки можно тут.
Ваш, @llm_under_hood 🤗
Google захотела сделать свой MCP протокол, только с крупными компаниями. Готово.
Назвали его A2A (Agent2Agent). Это открытый стандарт для обмена информацией между ИИ-агентами, работающими в разных системах. Он использует технологии HTTP, SSE и JSON-RPC для упрощения интеграции в существующую инфраструктуру.
Основные моменты:
(1) Dynamic Capability Discovery - агенты обмениваются данными через JSON-Agent Card, что позволяет выбирать подходящего исполнителя задачи.
(2) Task-Centric Communication - протокол работает с задачами, у которых есть свой жизненный цикл. A2A поддерживает как быстрые операции, так и долгосрочные процессы с обратной связью и уведомлениями.
(3) Security (за что критиковали MCP) - продуманы средства аутентификации и авторизации для защиты данных.
(4) Мультимодальность - обмен информацией в виде текста, аудио или видео.
В теории, общее назначение A2A - упростить автоматизацию и интеграцию процессов в корпоративных системах. Однако на HN люди уже высказывались насчет сложности протокола и его влияния на контроль над данными. Мол, нагородили всякого, лишь бы рынок отжевать.
Мне кажется, с такой компанией оно может и взлететь. Но из-за сложности и непредсказуемости систем лететь будет так себе.
Почитать доки можно тут.
Ваш, @llm_under_hood 🤗


Records
17.05.202523:59
14.8KSubscribers30.01.202523:59
0Citation index01.03.202523:59
5.7KAverage views per post27.02.202523:59
5.7KAverage views per ad post28.03.202521:13
7.82%ER27.02.202523:59
48.18%ERR16.05.202519:32
OpenAI Codex - по ощущениям похоже на Deep Research в своих проектах
Подключаешь к Github, даешь доступ к проекту и запускаешь задачи. И оно что-то там крутит и копошится, примерно как o1 pro / Deep Research. Только вместо поиска в сети оно работает с кодом в контейнере - запускает утилиты и пытается прогонять тесты (если они есть). Цепочку рассуждений можно проверить.
По результатам - создает Pull Request с изменениями, который можно просмотреть и отправить обратно в Github.
Потенциально выглядит весьма интересно. Deep Research и планировщику OpenAI я доверяю. А тут прямо можно поставить в очередь ряд задач и переключиться на другие дела.
А как это в сравнении с Cursor.sh?
Как говорят люди, это аналогично по качеству Cursor + Gemini 2.5-pro. Но возможность удобно и легко запускать параллельные задачи - это что-то новое (перевод цитаты с HN):
Ваш, @llm_under_hood 🤗
Подключаешь к Github, даешь доступ к проекту и запускаешь задачи. И оно что-то там крутит и копошится, примерно как o1 pro / Deep Research. Только вместо поиска в сети оно работает с кодом в контейнере - запускает утилиты и пытается прогонять тесты (если они есть). Цепочку рассуждений можно проверить.
По результатам - создает Pull Request с изменениями, который можно просмотреть и отправить обратно в Github.
Потенциально выглядит весьма интересно. Deep Research и планировщику OpenAI я доверяю. А тут прямо можно поставить в очередь ряд задач и переключиться на другие дела.
А как это в сравнении с Cursor.sh?
Как говорят люди, это аналогично по качеству Cursor + Gemini 2.5-pro. Но возможность удобно и легко запускать параллельные задачи - это что-то новое (перевод цитаты с HN):
По ощущениям, это словно младший инженер на стероидах: достаточно указать файл или функцию и описать необходимое изменение, после чего модель подготовит основную структуру пул-реквеста. Всё равно приходится делать много работы, чтобы довести результат до продакшн-уровня, однако теперь у вас как будто в распоряжении бесконечное число младших разработчиков, каждый из которых занимается своей задачей.
Ваш, @llm_under_hood 🤗
28.04.202510:28
Простой пример, почему не так просто добиться стабильной работы агентов/операторов на практике.
Смотрите на вот эту тестовую картинку. Задача у VLM на данном этапе плана - найти место на экране, куда нужно "ткнуть" мышкой, чтобы заполнить поле Lieferant.
NB: Я в курсе про BAPI PO_CREATE1 / SAP Fiori / SAPUI5 / итп. Тут дело не в этом.
Казалось бы просто - отправили в VLM и попросили. Так вот, даже GPT-4o начинает мазать и кликать не под текстом "Lieferant" а направо от него. Почему? ChatGPT объясняется так:
The mistake wasn't laziness, it was bias to SAP defaults + time pressure + separated information.
bias в данном случае можно перевести как "грабли", которые срабатывают внезапно и время от времени. Хотя любой студент без проблем ткнет мышкой не справа от текста, а в текстовое поле под ним.
Что делать в данном случае? См пост про системное внедрение LLM без галлюцинаций. Нужно крутить проблему до посинения, пока не получится решение, которое сводится не к игре в рулетку, а к инженерной задаче и возможности верифицировать качество каждого шага.
Ваш, @llm_under_hood 🤗
PS: А задача в итоге сводится к подобию того, что я описывал в истории разработки своего reasoning.
Смотрите на вот эту тестовую картинку. Задача у VLM на данном этапе плана - найти место на экране, куда нужно "ткнуть" мышкой, чтобы заполнить поле Lieferant.
NB: Я в курсе про BAPI PO_CREATE1 / SAP Fiori / SAPUI5 / итп. Тут дело не в этом.
Казалось бы просто - отправили в VLM и попросили. Так вот, даже GPT-4o начинает мазать и кликать не под текстом "Lieferant" а направо от него. Почему? ChatGPT объясняется так:
The mistake wasn't laziness, it was bias to SAP defaults + time pressure + separated information.
bias в данном случае можно перевести как "грабли", которые срабатывают внезапно и время от времени. Хотя любой студент без проблем ткнет мышкой не справа от текста, а в текстовое поле под ним.
Что делать в данном случае? См пост про системное внедрение LLM без галлюцинаций. Нужно крутить проблему до посинения, пока не получится решение, которое сводится не к игре в рулетку, а к инженерной задаче и возможности верифицировать качество каждого шага.
Ваш, @llm_under_hood 🤗
PS: А задача в итоге сводится к подобию того, что я описывал в истории разработки своего reasoning.
Log in to unlock more functionality.

